Getting Over Your Skills Issues

Skills are software whether you like it or not.
A list of instructions in a markdown file; how complicated can it be? Unfortunately, the moment a skill actually solves its job-to-be-done, it takes on all the same complexity that software does. We have a classic analogy here: let’s see why skills are the new spreadsheets.
You've probably seen the skills that everyone's talking about: a skill is a reusable context package for recurring work – instructions, examples, preferences, and sometimes files or scripts that tell an AI how something should be done. It is just one layer in the stack we give an agent to make it more capable: prompts are the one-off ask, MCP tools give it access to external systems and data, workflows define the multi-step processes we want it to run, and skills make those workflows come out the way we would do them ourselves.
Once you've nailed down how an agent can perform a repeatable workflow, you want to minimize the variance in the steps that matter: the format it follows, the checklist it runs, the preferences it respects, the edge cases it handles.
This is why skills are so appealing to less technical users. A PM, recruiter, lawyer, finance operator, support lead, or sales manager can create a useful AI artifact without first becoming an engineer. They are not trying to build infrastructure. They are trying to get shit done.
The catch is that a skill almost never stays a markdown file. The moment it gets shared, starts calling your tools, and becomes part of how a team works, it quietly turns into software – something with owners, versions, dependencies, and the governance questions that come with them. This post is about that drift: why it's inevitable, and how to manage it without killing the thing that made skills useful in the first place. But maybe there's hope after all.
We've seen this movie before
Let's consider the ur-business-software: spreadsheets.
In 1979, one person could calculate something at their desk without waiting on a programmer due to VisiCalc. It captured workflows and became a personal tool for folks to get things done.
Next, macros added programmability, and the analysts were essentially writing code. This was giving more tools and automation to the system and, inevitably, spreadsheets would be emailed and shared, and one file spawned a dozen. Worse, every copy kept learning on its own: people corrected their numbers as they spotted errors, so no two forks stayed in agreement for long. A fix that mattered to everyone had to be hand-integrated into each fork, one at a time; there was no quiet save that reached the whole company at once. Versions and change management were missing in a git-less world.
Live data, however, was the real Cambrian explosion. A workbook's answer started depending on systems outside it, spawning a wave of solutions – and new failure modes, like a feed changing and the sheet breaking silently.
Finally spreadsheets became systems of record: forecasts, quarter close, and pacing charts – oh my! One workbook that only one person truly understood, now wrapped in permissions, version history, and reviews.
Spreadsheets complexified to capture and store business logic that colleagues needed to execute their tasks; skills are complexifying for the same reason but for agent colleagues. Spreadsheets became such an explicit representation of the work that needed to be done, that ability to use them was a firm job requirement across many industries and titles.
Where are skills in this doomed, repeating history? Speedrunning it all: confronting each of these evolutions simultaneously, leaving our current state feeling jagged.
Most skills are still in the VisiCalc moment: a local Markdown file that a client like Claude Code, Cursor, Codex, or opencode reads and follows well enough to feel powerful. However, skills are escaping containment. Business partners are asking for each other's skills, asking why it doesn't work on their machine, and asking for support to customize it to their workflows. This is exacerbated by uneven clients and agent homes, so that even for a single user, skills need to be portable.
Agents' hunger for tools and access are thrusting us into the live-data moment: the skill and its tool contract have to stay in sync, and a skill bound to an MCP server is only as dependable as that server. Packaging them together helps, but it quietly drags ownership away from the domain expert and toward something eng-owned and managed.
The systems-of-record era is arriving as plugins with repo-backed distribution, which bring version history, review, and automatic updates. So now the less-technical users need to concern themselves with branches, pull requests, and releases. So much for just asking your agent to update as it goes.
The skill complexity matrix
A few agent written paragraphs in a markdown file, then a step that calls an MCP tool. Your teammate is a bit jealous, they also want to do this – but their workflow is a tiny bit different. You're on the train the week after wishing you could use your skill, but you never get a seat so you're trying to do this from your phone. How did a throwaway markdown file quietly become something you and your team are relying on? Skills creep, and they do it along two axes at once.
The first axis is capability: what a skill is actually able to do. The simplest version of a skill is really just a prompt: a block of instructions and context that shapes how the model answers, without reaching outside the conversation. But the value of a skill lies in what it is allowed to reach. Does it have access to files (upload/local/cloud access), and can it write them as well as read them? Can it run code on your machine or a cloud machine? Can it call an external API or query a database? Can it make authorized requests to some system? Every yes widens what the skill can do, and what's necessary to make it work. At the far end, a skill can't run at all without specific tools behind it: an MCP server, an internal service, and infrastructure to make it always available.
The second axis is distribution: how far a skill travels, how many hands shape it, and what it costs to change once it has. The simplest version never leaves your laptop: a file you wrote for yourself, edited if it annoys you, seen by no one else – when you learn something, you just fix it, and the only person who lives with the change is you. But because sharing is caring, before you know it you're asking who depends on it and who is allowed to change it. Is it pinned to one machine, or synced across all of your environments? Have you DMed it to a teammate, dropped it in a shared directory, or published it somewhere internet randos can install it? Applying what you learn no longer just saves the file; it requires a release, and those changes need to percolate to everyone (or do they?). Updates need not be yours at all: a skill that rewrites its own instructions as it goes may feel like continual learning on the cheap, but learning for whom? The more it’s a shared resource the more the learning needs to be reproducible and understandable. At the far end its shared infrastructure: live updates, data rich, and everywhere available.
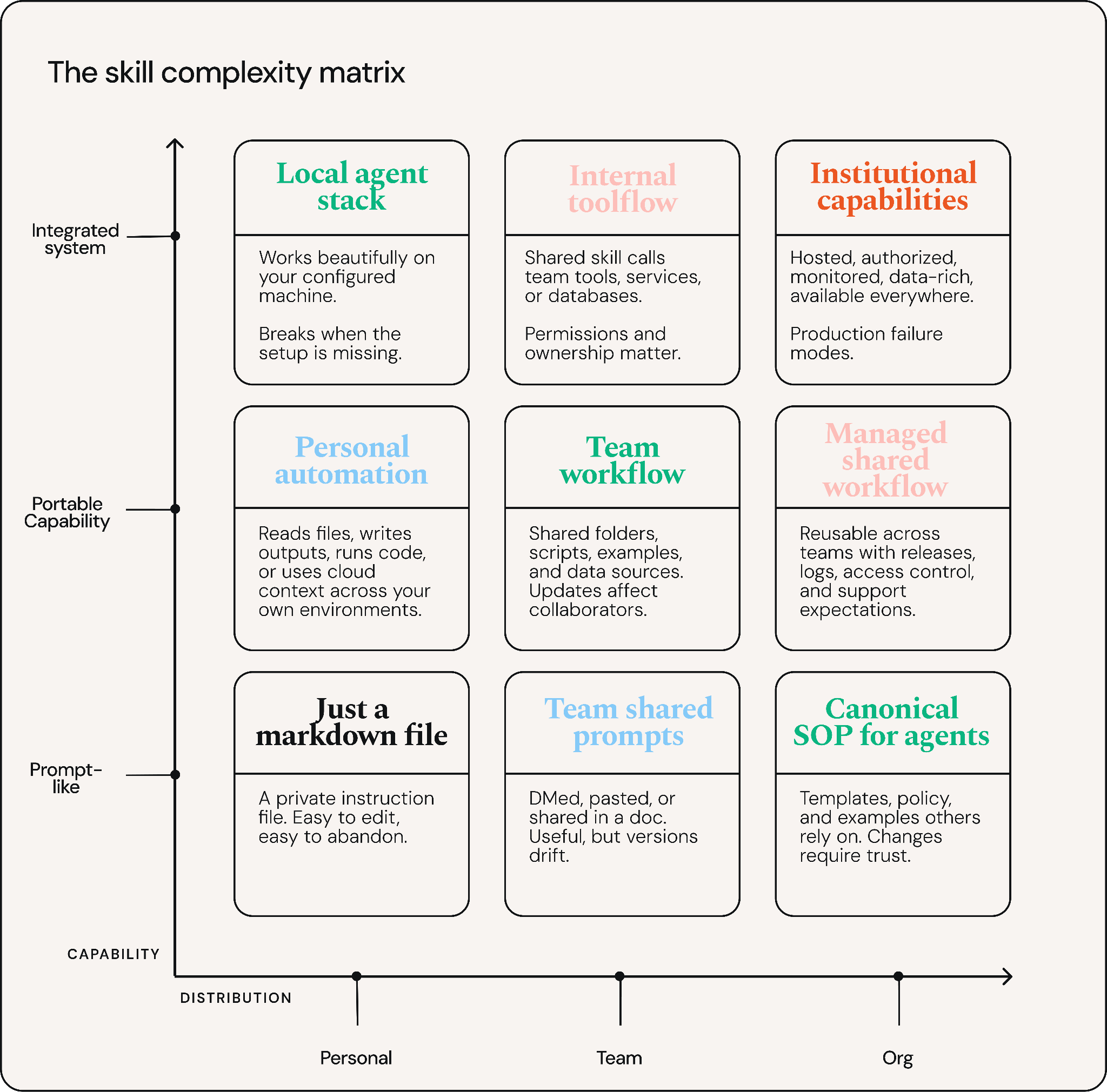
A personal instruction file and a shared, tool-using business workflow may both be called “skills,” but they do not have the same failure modes. The farther a skill moves along either axis, the more valuable it can become. The farther it moves along either axis, the more coordination, maintenance, and governance it requires.
One step at a time
These are software questions: who owns it, who can edit it, what it can access, what breaks when a dependency changes. We climb through the matrix because we believe in the payoff, and remember, we have names for this progression: YAGNI, the rule of three, make it work, then right, then fast. [1] [2] [3].
What is new is the speed at which we'll want to progress. The low floor enables a much broader group of users, and with it more skills across a broader surface. A larger TAM means sharing comes sooner, and broader settings in which they want to be used. Additionally, given the time we're in, expectations are high – of course everything should run on every platform, keep a memory, auth to each system at your workplace, and butter your toast.
The goal is not to turn skills into software, but an engineering mindset can be helpful in shepherding skills through. Unfortunately, dear reader, in addition to technical challenges there are also organizational challenges ahead. But it's important to remember right now that we're getting what we always wanted: the subject matter experts are actually interested!
A patchwork setup
Moving up and to the right moves up the ladder rungs, and each rung changes how you should deliver the skill; match the mechanism to the rung the skill is actually on, not to the top of the ladder.

You shouldn’t require uniformity in skill maturity across your needs: some can stay local files while others ship as MCP resources. This non-uniformity has a cost though, organizational confusion and an operational tax, but it's often a price worth paying to fight against the demon of complexity.
- Single-user, single-client, single-machine skills can just be files. Keep them local, ask your agent to update them as you work, and back them up like any other file.
- For static skills shared across people or machines, lean on your client. Pick the client your team standardizes on and upload the skill to it once per user or terminal.
- If Skills can evolve, start adding versioning (and maybe review). If everyone is on local coding agents, ship the skill to shared storage and let each machine pull it as a file; from there you can opt into version control, and opt into requiring review from others.
- Skills that call authenticated tools should travel with whatever manages that auth. If a skill reaches a third-party MCP server, deploy a wrapper around that server that also carries the skill; today, packaging skills as MCP resources is the cleanest way to do this.
- Shared, automatically adapting skills need a system of record. That's where reproducibility starts to matter: you want to know which version of the skill produced which behavior.
Think of each of these as milestones to graduate to the next stage of infrastructure complexity. Don’t be excited about leveling up your skills infrastructure, stay excited about how much value you can add to your organization’s workflows with the minimal investment in these extra systems.
The world of tomorrow
So what's missing? We have Dropbox and symlinks and GitHub and PRs. We already know that engineering teams can make skills work, but what's less obvious is how to create workflows that let less technical people (and agents themselves) create, share, review, and improve skills safely.
Skills need a registry; maybe. Discovery is important, and a registry can help there. But many clients already have a simple way to surface what’s out there. What can be useful is the ability to push updated versions of things to other users automatically, and make it easier for others to not get out of sync. At Theory we're using Claude Enterprise to administer some skills, but primarily packaging them with our internal MCP deployed via Prefect's Horizon.
Reviews will be required. Everyone shouts that GitHub is dead, and it's easy to understand why: a code review UI may not be the friendliest for folks less used to it. What's essential in a review workflow is the ability to understand what's in the skills, what might be changing – and in a perfect world – see sample runs/examples. Demos comparing changes and versions will super-power adoption and curiosity. Early progress in this space can be seen in moxn.dev, focused on being a CRM for documents with a nice review workflow.
No RSI before a system of record. This is the gap with the most startup opportunity. A skill that rewrites itself via usage sounds great, but will beget a new black box before you know it. Provenance of updates is essential and will need to plug into the review workflow above. For tracking usage and building self-learning loops, at Theory we built our own light middleware layer (only works for MCP deployed skills) that writes the data to MotherDuck, and is then exposed via the MotherDuck MCP.
At Theory Ventures, our users of all technical levels are creating skills; they’re making local files for Claude to use, sharing via DM, asking our engineering team to integrate with MCP, deploying to our Claude enterprise account, and living in the future.
It's too early to say a single solution is needed spanning these areas, but one thing is certain: user and agent experience will matter in making a Skills lifecycle great.
Skills are not just better prompts, they are a new place to encode how work should be done. They’re exciting because they let the people closest to the work shape the agent’s behavior directly.
As skills become shared, connected to tools, and embedded in workflows, they also become infrastructure. The challenge is to let them mature without losing the reason they worked in the first place. We may have already left the era of box-and-wire AI workflow builders; not because people don't want them, just because agents got too good too fast.
Spreadsheets are the most successful data product ever conceived, deployed across the entire range of user capability. Skills can speedrun this journey.
