Automating Slides to Signals
Five years ago, a simple workflow automation task seemed not worth the effort. Now, everyone’s asking themselves how aspects of our workflows can be transitioned to automation via AI, or at least augmented by AI.
Unfortunately, this process has headwinds. The most common issues are usually related to the complexity of the workflow, the availability of interconnected tools, or model performance. Of these, model performance is often the easiest to overcome, as its challenges can frequently be mitigated through effective human-AI collaboration.
During my internship at Theory, I focused on model performance within workflows: turning unstructured and nonuniform information from startup board decks into clean, structured data that investors could utilize.
Startup’s board decks often contain crucial information about a company’s performance and priorities; however, they arrive in a variety of formats. Some have clean tables. Some have beautiful but dense slide designs. Many decks hide important metrics inside charts, graphs, and images.
We want easy access to these data, which today sit locked in disparate sources. We also want the ability to slice, join, and analyze them without burdening our investors or portfolio companies with manual data entry.
Our key criteria for this work were:
- Highly automated processes that fit into simple workflows,
- high accuracy and high trust in the data collected, and
- compatibility with other data systems and applications to enable analytics workflows.

Hence, the Board Deck Extraction project was born.
Core Components – Why Were They Chosen?
Email Ingestion
To satisfy our first criterion, we needed a frictionless method to get the decks into our processing system. Our first solution was to send the board deck PDFs to a service email account and use an Apps Script to poll that email for board deck-related emails. No deployments necessary, just a lightweight, scheduled polling script.
This ended up working well enough, so we stuck with it. Additionally, Google Apps Script is completely free, and we were already using Google Cloud Services as our cloud provider.
Text Recreation
Page layout, page co-occurrence, and multi-page context are all crucial in extracting the meaning of text. This means that pure text extraction was likely not enough.

Our goal was to send the LLM strings of text for processing, so our initial naive solution was to run the PDF through Tesseract OCR in Python. While this worked for text recognition, it flattened all formatting, losing the page structure, table alignment, and any sense of where data lived in context. A number in a table could be sitting beside the wrong label, and Gemini wouldn’t know the difference.
That’s when we turned to Google Document AI’s Layout Parser. Unlike traditional OCR, it:
- Identifies blocks, paragraphs, and tables with their spatial relationships,
- supports mixed content (text + images), and
- outputs a structured JSON representation of the document.
This meant we could rebuild the document as text with layout preserved, giving Gemini the context it needed to correctly interpret table data, extract numbers embedded in charts and graphs via image OCR, and understand relationships between headers, subheaders, and values. While there are other services specifically designed for applications like this, the Layout Parser was an easy and effective option already pre-existing in our GCS infrastructure.

The result? Accuracy jumped, and Gemini could now pull metrics from places that had been previously out of reach.
A Note on Evals
Evals are a crucial part of any LLM capability. We used some simple hand labeling of board decks data and a homegrown app to try different prompts, products, and services for these tasks. We didn’t go too deep on measuring fancy statistics or metrics about the quality of extractions; we just stuck to simple accuracy and instruction following for these tasks.
However, we did test out multiple evaluation platforms and each of their usefulness to this project. We performed an evaluation on the evaluators.
Metric Extraction
It’s easy to frame the objective as a simple yes/no, “did it extract the text correctly?”, but the reality is more nuanced. This task is closer to translation than to straightforward text recognition.
Let’s use a simple example: some metrics (e.g., burn rate) aren’t always present and must be calculated. As is known, LLMs are arithmetically challenged, so how should we get the LLM to calculate it? The answer is via tools. Using Gemini with Vertex AI, you can ask it to extract metrics and write code to calculate new ones. This is extremely useful, especially with metrics that have a triangular relationship. For example, if we are provided a cash balance and a monthly runway, we can extract them with Gemini and use Vertex AI to generate code to calculate burn rate.
.png)
Evals became even more essential in this stage; we are asking the model to perform a series of steps where a mistake at one step ruins the chances for the rest of the steps. By creating a ground truth for every metric extraction, we are able to evaluate each model and prompt’s accuracy.

The prompt was essentially built through iteration: write prompt, analyze errors, incorporate into prompt context, repeat. There are plenty of platforms that offer an application workflow for this process, and we even developed our own internal app to streamline this. However, for much of this work, we used Google Sheets.
Metric Verification
This workflow deals with some critical data. For this reason, we decided to create a human review step. While humans should not be relegated to computer verifiers, this is a good use case while we build confidence in the consistency of the capability.
To make this work as pleasant as possible, we created a UI experience optimized for rapid review:
- Side-by-side context: Metric value + originating page number + option to be automatically taken to originating page.
- Definitions & explanations: Each metric’s meaning and extraction rationale.
- Save state: Progress can be preserved during reviews.
Story in Data
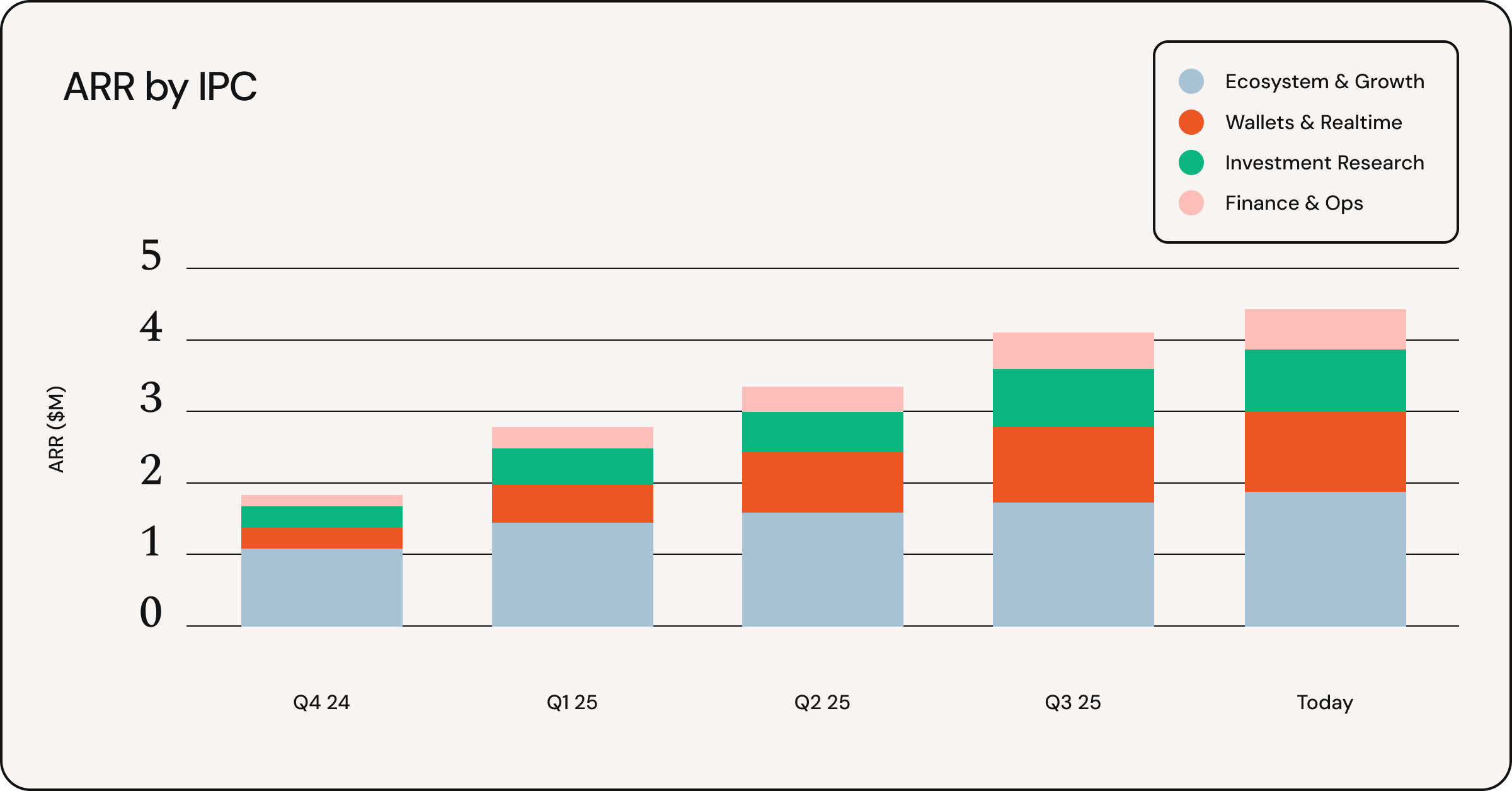
Now that we have the data extracted, we can finally start unearthing insights.
Think of a collection of board decks as a story, and each deck is a chapter. With these metric extractions, we can easily summarize while maintaining and visualizing the key points that drove the story.
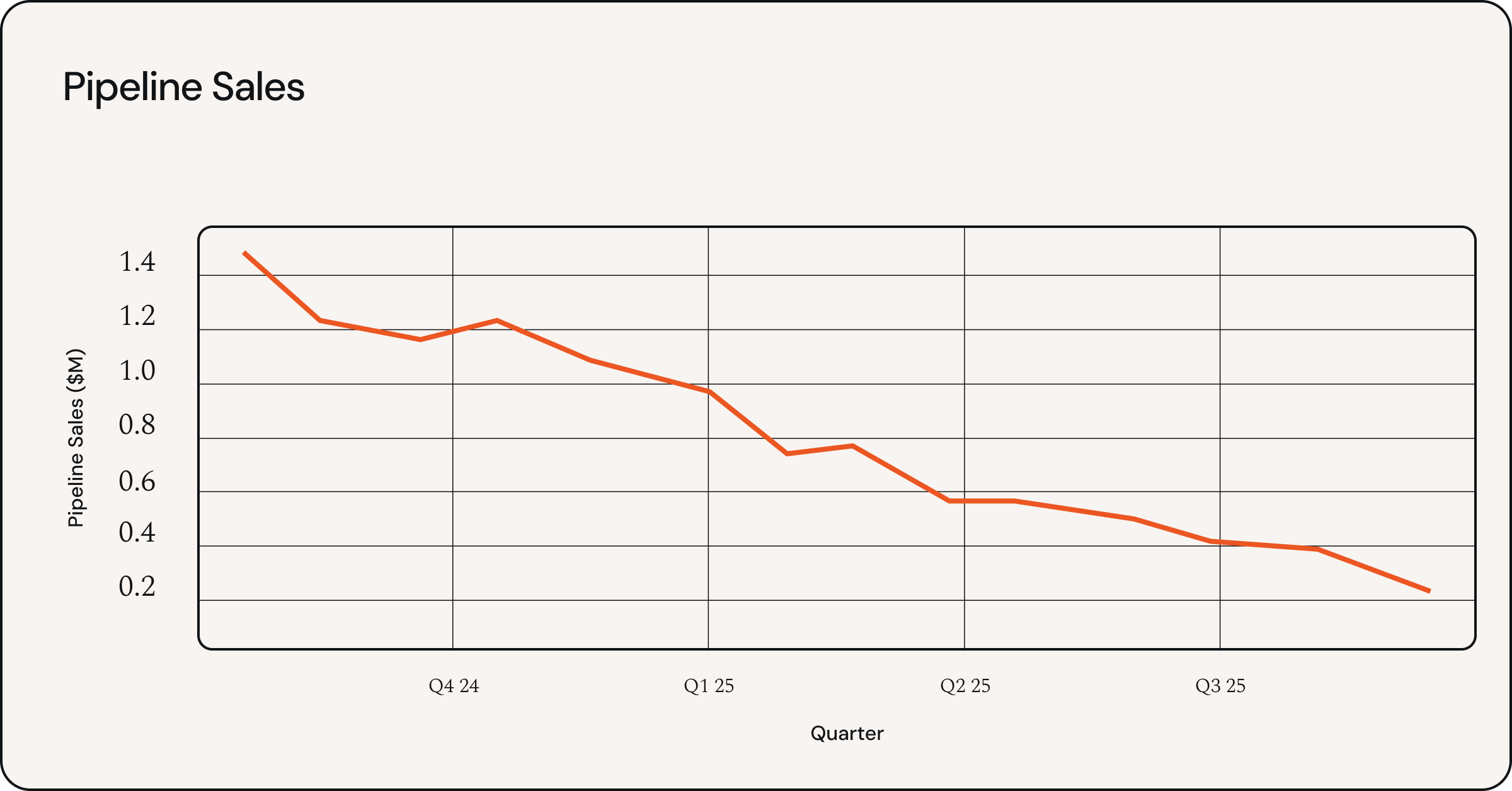
Here, we can easily surmise that something isn’t going well. The raw board deck itself cannot display this level of clarity to a company's story.
From Manual Work to Automated Workflows
Five years ago, hiring a dedicated worker for these kinds of tasks was normal. Automation tasks for unstructured data just couldn’t be viable. Today, it is.
With effective human–AI collaboration, we can overcome common pitfalls and achieve workflows that are both streamlined and reliable, delivering high-accuracy and trusted data.
At Theory, board deck extraction is only a fraction of the beginning. We’ve built an entire system of internal services that speed up our workflows, focused on speed and quality. This is just one service among many, and we intend to keep pushing the boundaries of how far AI augmentation can take us.

