Foundation models will kill the traditional moat of ML applications. What new ones will emerge?

Introduction
LLMs will all but eliminate the moat of a proprietary ML model.
ML companies have typically built a business with their model as a moat. Create a product, collect data, improve the model, repeat. With this flywheel, competitors can never catch up.
Companies building LLM applications will not be able to create truly defensible models. Instead, they should focus on data moats in the surrounding LLM system and infrastructure.
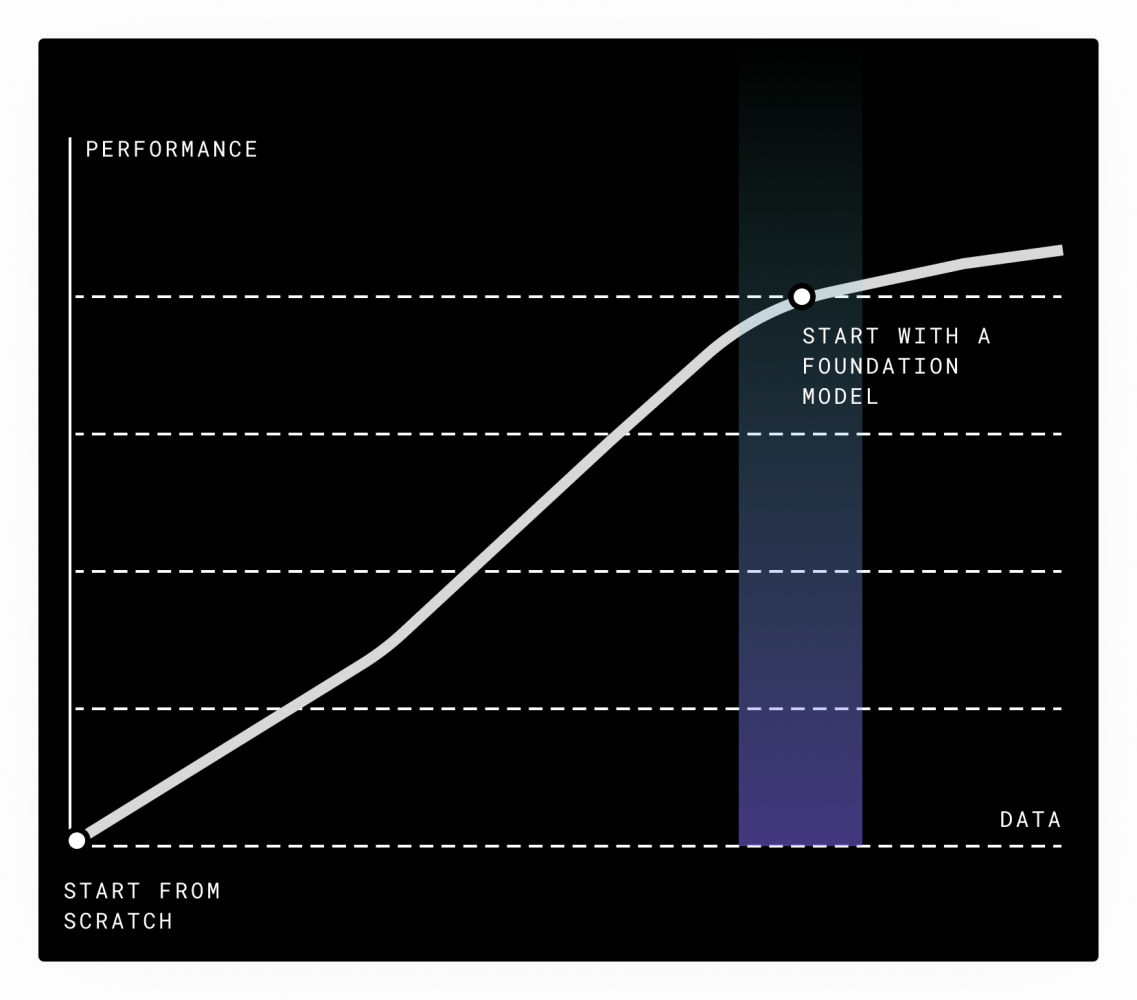
The power of modern foundation models like LLMs is that a single massive pre-training run (sponsored by a big tech company or well-funded startup) allows them to do a wide variety of things well out of the box. With a small number of additional examples, these models can be refined to do even more specialized jobs.
When you’re training a model from scratch, the more data you have, the better – the model has a lot to learn.
With a foundation model, you’re starting much further up the curve. There’s less room to improve – and less distance for others to make up.
Fine-tuning is and will remain important to refine how a model responds to a query – whether it should be concise, use certain language, or be in a specific structured format. But it will not be a durable advantage that grows over time.
Many business workflows are composed of simple tasks, like data entry or document summarization. LLMs can do these jobs well enough off the shelf or with limited fine-tuning, and there will be diminishing returns from additional data.
Use cases that challenge today’s LLMs will benefit from larger amounts of fine-tuning data. But with each new generation of model, LLMs handle more tasks with ease. These moats could be destroyed at any time as models progress.
The new data moats in LLM systems
As explored in the LLM infrastructure stack, the model is just one small piece of a broader system that will be necessary for complex LLM applications.
While maintaining model superiority is no longer a sure bet, there are new opportunities to build data moats in other parts of the LLM stack.
Context and retrieval systems
For the foreseeable future, LLMs will rely on external systems to serve them with relevant information at inference. A support chatbot will be provided with a customer’s order history. A financial research analysis platform will pull in relevant company filings.
As LLM systems mature, context and retrieval systems will be just as, if not more, important than the models themselves. Data moats will provide huge advantages in this space:
- First, proprietary data will be used directly as context. As some have put it, context is the product. LLMs can be provided with past queries, user interactions, and other product data to enable new user experiences and more relevant responses.
- Second, usage data will help improve retrieval systems. It will inform better data architectures and retrieval logic. This data can also be used to train learned models for embedding and search.
Orchestration and workflow design
LLMs are great when instructed to do a simple knowledge task. They’re not as good at being their own boss and deciding what to do next.
LLM applications will rely on traditional software, logic, and other learned models to coordinate their broader workflows.
Imagine an LLM data analyst. You could instruct it to “show me a chart of our active users.” It might generate a reasonable chart, but it would be hard to tell if the result is accurate.
A well-designed workflow might instruct the LLM to complete a series of discrete tasks. First, evaluate the request and identify which table it’s asking about. Next, select the relevant metric from a predefined list. Third, generate a SQL query (via an LLM or other SQL generation tool) and return the results. Last, plot and format them.
Proprietary data will allow companies to improve these systems over time. Usage data might inform new rules-based logic or learned helper models to help guide an LLM workflow. Historical queries can be used to optimize prompts, caching, or model choice.
Handling edge cases as a competitive advantage
LLM systems in production will be complex systems almost like living organisms.
Today, engineering organizations are designed to handle deterministic software. Bugs and new features get ticketed, and then an engineer creates a PR to fix them. Companies that have ML teams have a separate workflow where they compile data, update the model, and backtest it.
Companies building LLM systems will need new workflows to handle non-deterministic edge cases and shape an LLM’s behavior over time. They’ll trace each interaction throughout the infra stack to understand what went into each request and response. Resolving an issue might require fixing a retrieval system, re-engineering a prompt, fine-tuning the model, or improving the orchestration system. These might all be done by different roles in an organization.
Building data-informed systems to deal with edge cases will be a key differentiator over time. This workflow is most similar to historical ML moats. But instead of putting data towards model re-training, it will drive a more holistic process to improve the broader LLM system.
Conclusion
Data moats in foundation model applications will look very different from previous generations of applied ML systems.
We believe the strongest and most durable ones over time will not be fixated on maintaining the best-performing model over time.
Instead, founders should take a high-performing model as a given, and try to build data moats in everything surrounding the model – the systems that tell the model what to do, provide it with data, and monitor its outputs. Operational data accelerates the capabilities of each of these systems, increasing defensibility over time.
If you’re building an LLM application and are thinking about data moats we’d love to hear from you at info@theory.ventures.
