The Hunt for a Trustworthy Data Agent

The first competition pitting AI agents agains the messy reality of modern business data.
The internet would have you believe that AI for Data is a solved problem. This claim is often stated as a corollary to ‘text-to-SQL’ being solved, and ‘ripgrep is all you need’.
Unfortunately, the reality of the modern enterprise is not a simple data warehouse, a nice Google Drive, and a log store that makes sense. It is a sprawling, messy ecosystem of structured tables, cryptic server logs, and endless folders of PDFs.
Data analysis has always been one third investigative work, another third engineering tools, and a final third decoding context hidden in questions. So while a tightly scoped question on a provided data schema may give the impression that text-to-SQL is a problem for 2023, there’s work to be done in building AI assistants for ‘quick questions’.
A Hill Worth Climbing
If you want an LLM capability to exist in the next 6-12 months, your best bet is to build a benchmark – so we did. We have seen exceptional progress on chat and coding, but robust benchmarks for complex, multi-modal data analysis simply do not exist.
To test the limits of current agents, we didn't just want a Q&A dataset on a fixed schema; we needed a simulation of reality. We built a fake business called Retail Universe from the ground up to serve as the backdrop for a true "data mess." Creating this benchmark was a significant engineering effort in itself, consisting of:
- A Realistic Data Warehouse: Constructing a Kimball-style star schema with 17 dimension tables, 7 fact tables, and over 3.3 million rows of data.
- Messy Logs: Generating nearly 7.7 million log lines across 18 different types and 5 distinct formats (including TSV, JSONL, and Syslog) to mimic a complex backend.
- Unstructured Documents: Creating a repository of over 97,000 PDF documents covering 11 distinct business types, ranging from sales receipts to warehouse picking slips.
On November 15, over 100 people gathered to throw their best agents at this wall of data. The goal? To see if AI can answer the kind of specific, high-stakes analytics questions that drive real businesses.
The challenge was to solve 63 data science and analytics questions about Retail Universe. Here’s an example:
“Our largest customer in 2022 should sign up for a recurring order program. Which customer, which item, and how many months did they order that item?”
Or another one:
“We ran a signup promotion #102 in Q1 2020 for $20 off their first order. Calculate its ROI based on 12-month value, assuming all signups are incremental.”
For readers who have experience working as a data scientist, these may feel familiar, but with one conceit: the desired answers are extremely specific.
This competition was presented in four phases:

Contestants submitted solutions to the questions as CSV files with a column for each of the ‘checkpoints’ along the way to a correct answer. For example:
“Sales for an item spiked for a few weeks, but revenue is down. Figure out which item and calculate the lost revenue.”
Expected output:
{
"item_sk": 2,
"lost_revenue": 45770.69
}
Which was graded automatically, and the results for each key were returned. A point was awarded if they got all the values for a question correct.
Over 6 hours, folks battled for prominence in our simulated world of data analysis showdown.
But we had one final gimmick: a human data analyst with 20 years of experience but no AI tooling, – a human baseline.
His team name: John Henry (aka Elliott Star).
Outcomes
Our winners were:

Note: in the last minute, TableFlatteners tied up the score with ChrisBerlin, and we had to go to a thrilling showdown: I asked three questions where the two teams had to race to solve each one; best of 3 won.
Here’s how the teams performed, based only on questions where no answers were provided:
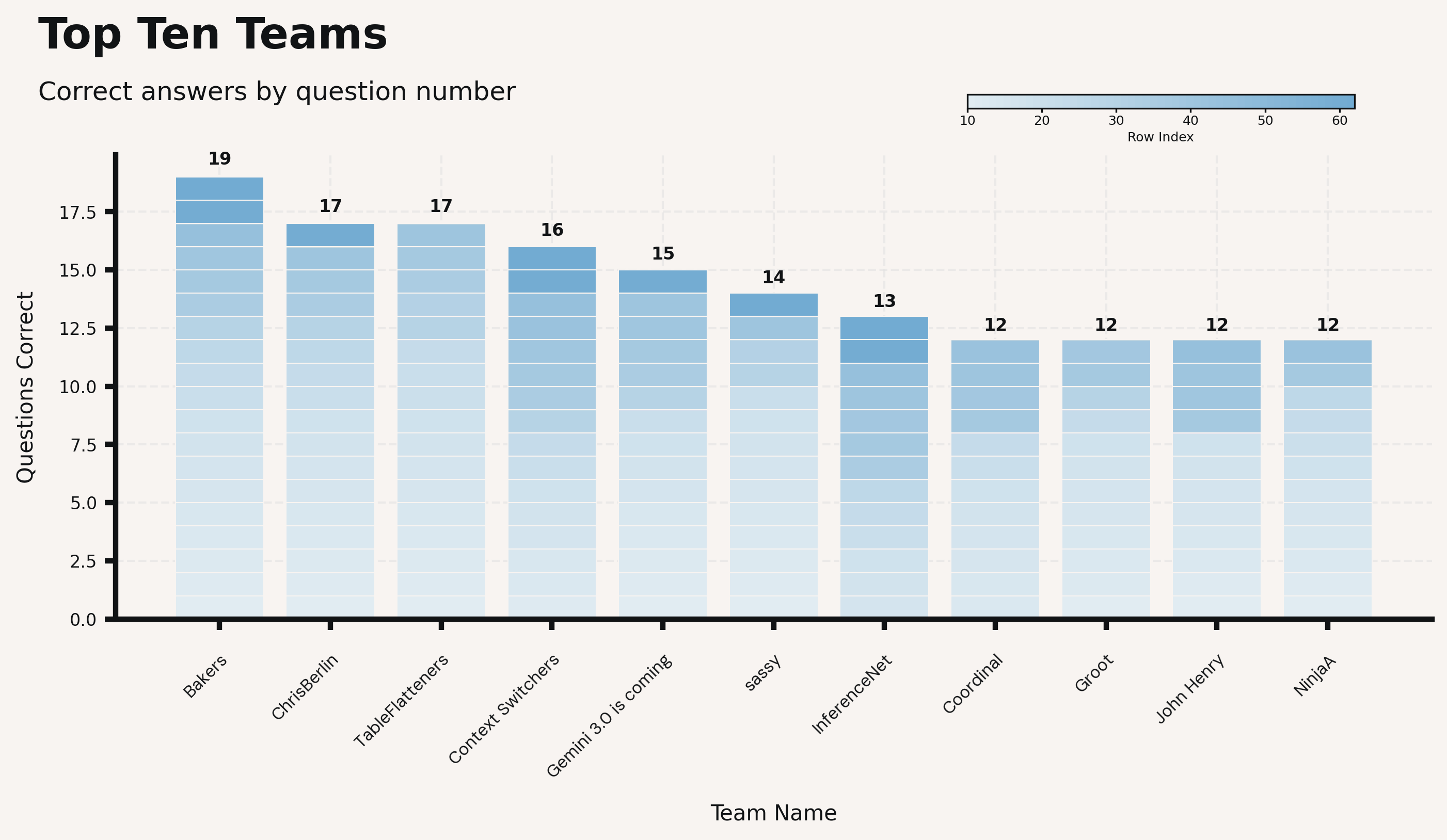
While the best performing teams solved less than half of the challenges, a real evaluation of performance looks even less rosy:
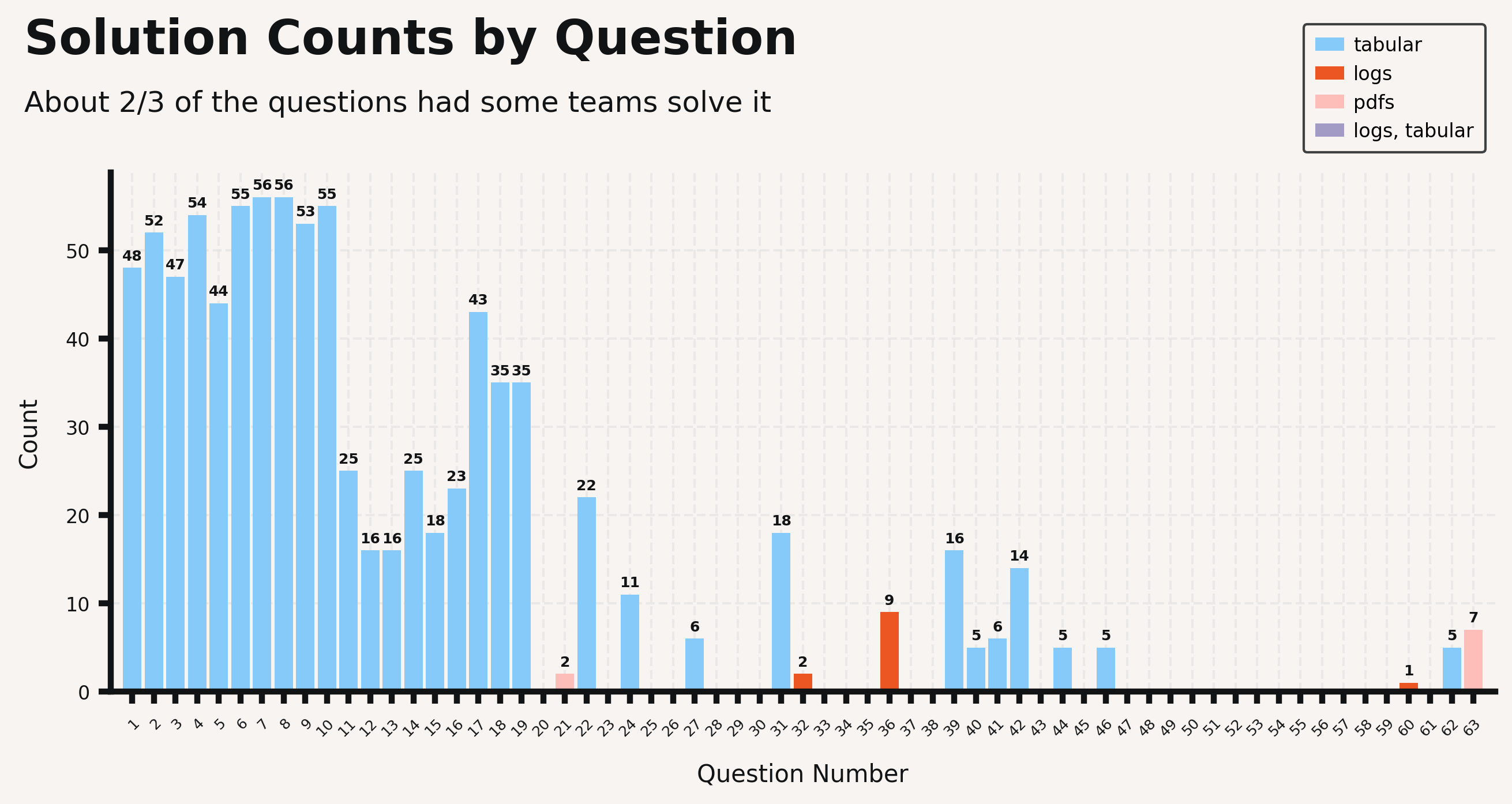
You can see here that beyond the first 10 questions (which we gave the answers to), performance was quite poor on many questions, and over a third received no correct solutions.
If we relax to look at all checkpoints, not only full solutions, we see a bit more spread across the challenge:
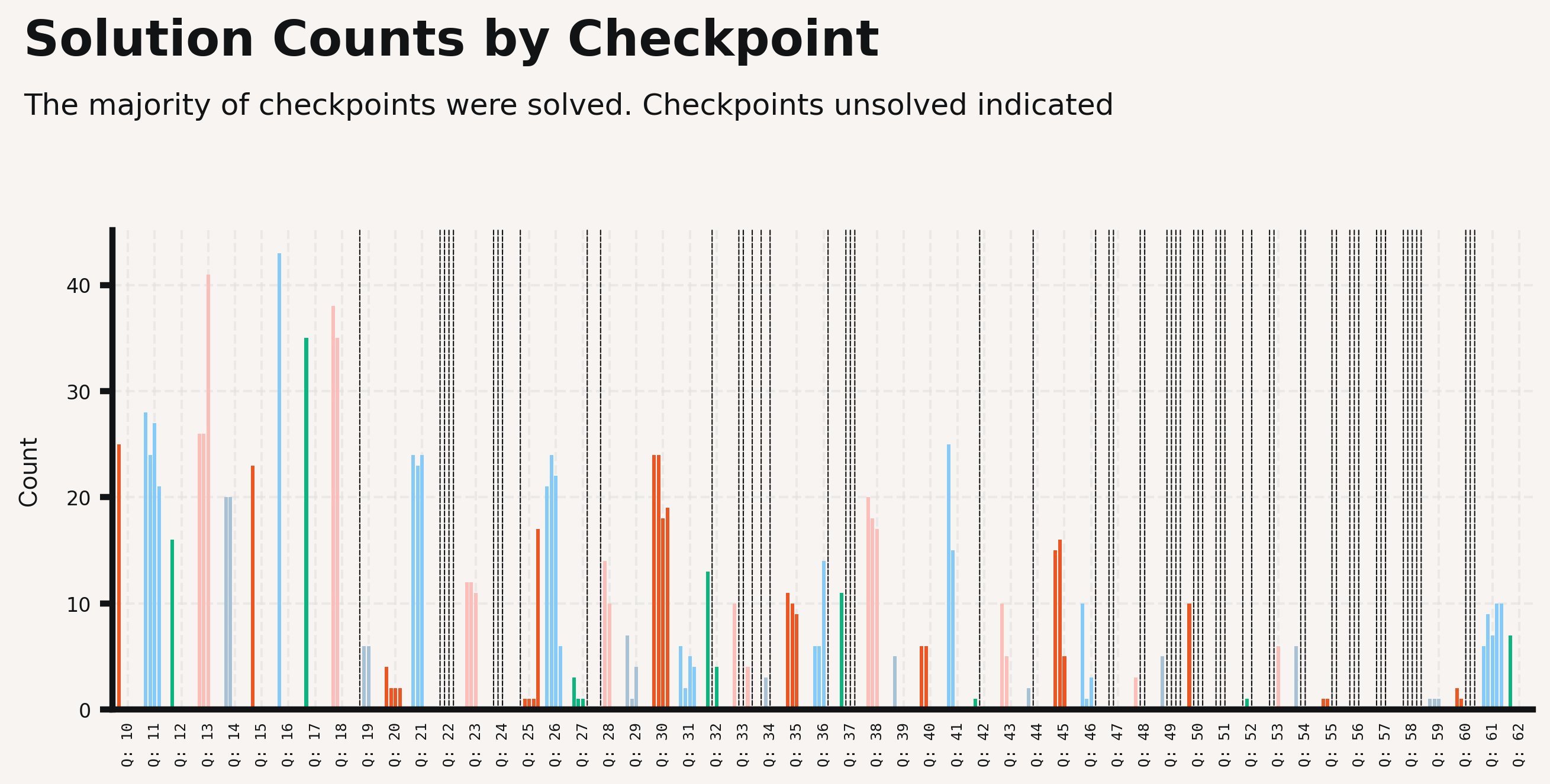
So our first insight is that most of the checkpoints had some correct answers.
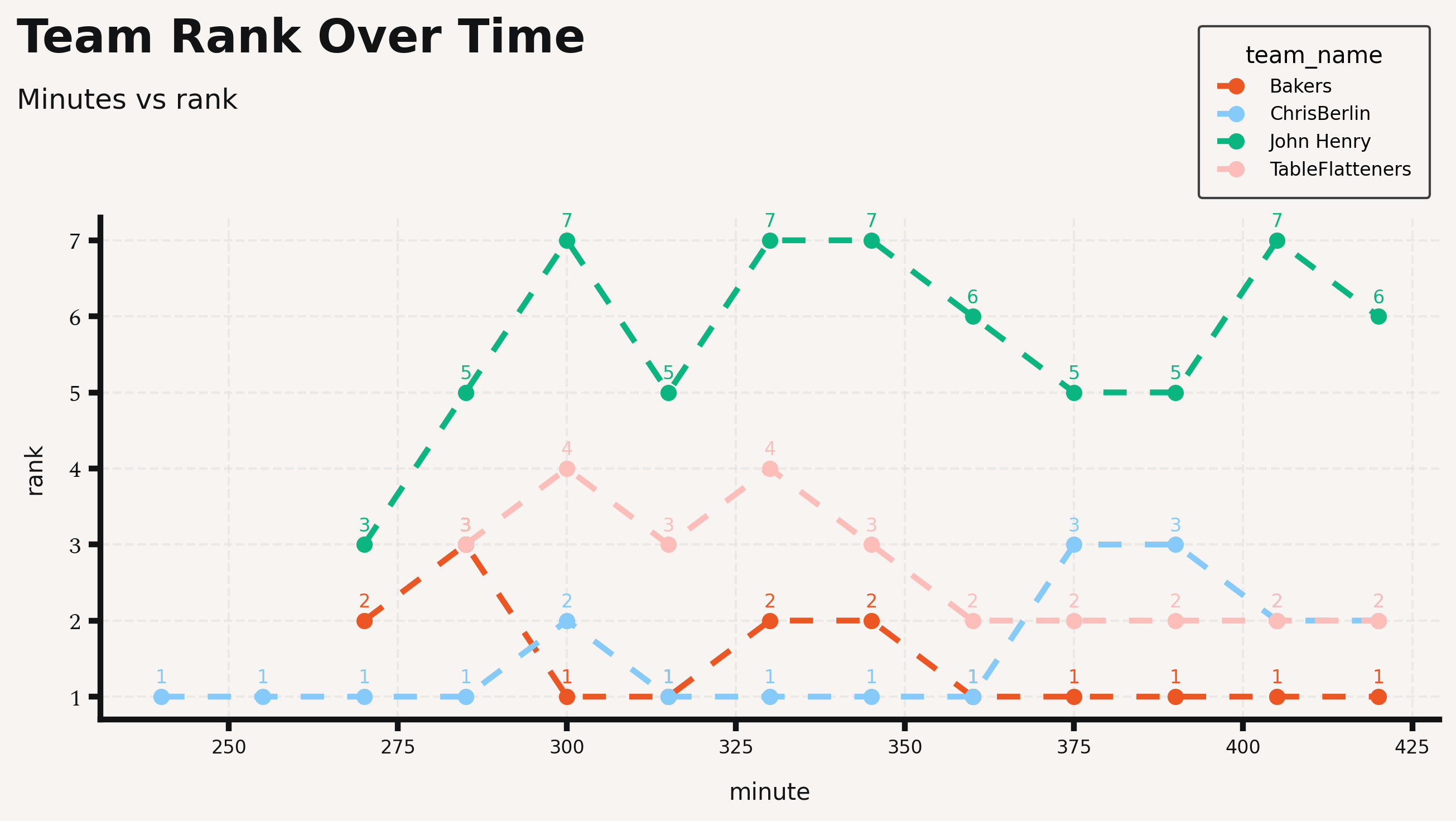
The next thing we wondered was how the day unfolded for the top 10 teams:
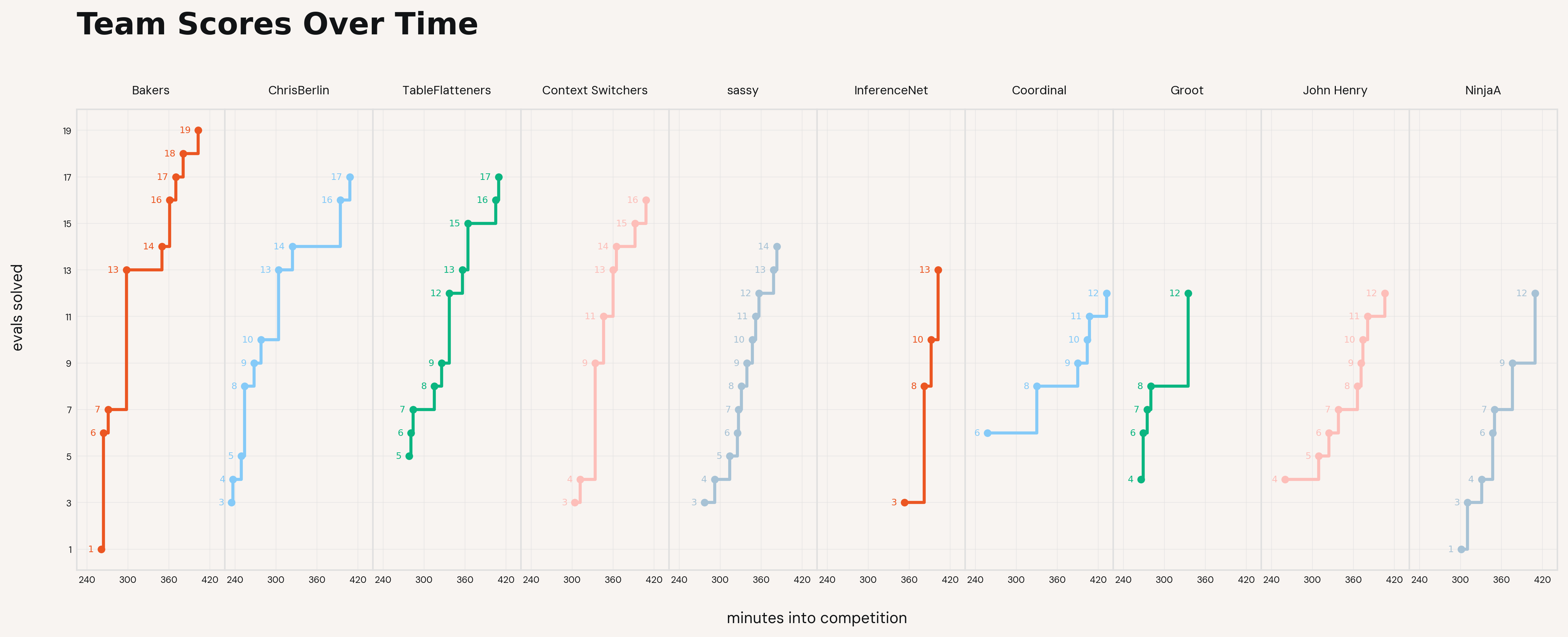
Several teams would clear multiple evals at a time, and the majority of the action happened around minutes 300-330.
You can also see that after our top teams (and human baseline) premiered, they stayed in the lead:
We looked at both contestant and question correlation of solutions, and while they made pretty heatmaps, there weren’t any impressive seriations worth talking about.
What We Learned About Data Agents
If you watch the interviews with the winners, they knew virtually nothing about Retail Universe. It would be nearly impossible to answer any questions as a data scientist for a real company with the lack of knowledge the participants had. Imagine attempting to explain sales phenomena at your organization while not knowing the number of stores you have, where they are, or even your most popular items.
The winning solutions, and many in the lower tier, didn’t build data agents; these teams simply used pre-existing agents like Claude Code, Cursor, and Codex, and asked them to write code to solve the problems. As part of the setup for the challenge, we gave them access to a MotherDuck MCP for easy use of the tabular data and LanceDB instructions for easy use of the PDF data.
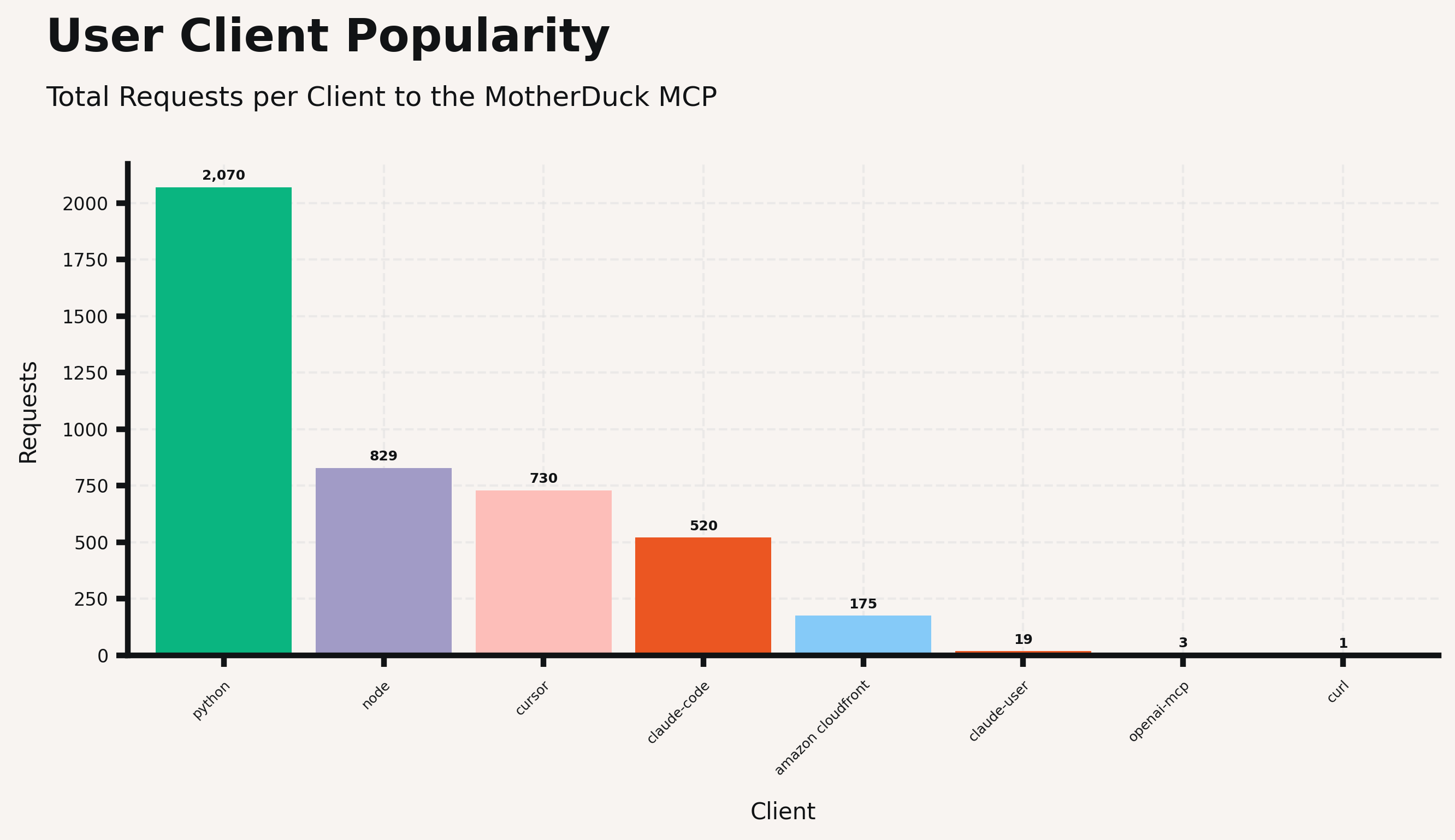
We saw a lot of usage of the MotherDuck MCP, and the winning solutions even called out how useful it was for exploring the tabular data. You can see how, amongst the teams using this MCP, different clients' popularity broke down, and you can see how many requests to this MCP were made over just a few hours. Similarly, we saw several teams utilizing LanceDB to make searching over unstructured data much simpler.
This brings us to the first lesson:
Many data problems are coding problems if you squint hard enough.
The agents grepped and parsed and regexed and scanned as much data as they could. They build ephemeral assets to assist them with a laser focus on the task given. And when they confidently landed on an answer, they spit it out. Unfortunately, most of the time, what they spit out was wrong.

Our second lesson:
If you give people unlimited tries, they won't build trustworthy agents.
We chose to give contestants as many submissions as they wanted, without penalty for incorrect answers. This was a mistake. We could have incentivized building trustworthy systems by limiting submissions to 1 incorrect attempt per checkpoint. Future iterations on this challenge will be graded in a smarter way.
Our number one learning about this event:
If you ask people to compete on a set of explicit evals, hill-climbing won’t move towards a useful agent.
A useful data agent is similar to a useful data scientist; a trustworthy, curious, technical partner – one that helps frame the question that can guide a decision. While we learned a lot about the current capabilities of models in investigating data, we aren’t yet confident that we’ve seen a useful data agent just yet.
Look forward to follow-up details on this dataset as a benchmark! If you’re interested in Data Agents and would like to partner with us on evaluating yours, please email bryan@theoryvc.com.
