Evaluating The Evaluators

The LLM operations space is crowded, and differentiation is fading fast. Platforms race to match each other's features, leaving users to wonder what really sets them apart.
During my internship, both because I needed to evaluate these capabilities and because I wanted to understand the landscape better, I ran a deeper comparison across the major evaluation platforms.
In my last post, I mentioned that we tested several tools and assessed their usefulness in my Board Deck Extraction project. To understand how the user experience differs across platforms, I built a small dataset of two mock board decks and designed a set of evals to judge each platform’s output. I gave myself around two hours with each platform to trace, evaluate, and refactor my prompt.
Helicone, Braintrust Arize, LangSmith, and Weights & Biases Weave were the candidates of this test. Each platform was graded on the integration process, specifically the ease of integration, duration of setup, and the amount of refactored code, out of a total score of 30.
The quality of features was also graded out of 30. 20 for how well it does its job, and 10 for the look, feel, UI, and UX.
The quality of aid to my issue was graded out of 10, for a final score out of 70.
Helicone
At its core, Helicone is a platform for tracing LLM calls and reporting each call’s statistics. They aren’t really an evaluation platform, and even say so themselves. Even so, I tried using the platform as such for the purpose of this experiment.
The setup was relatively easy. I was able to configure traces for my LLM calls within 20 minutes. From there, I created my own evaluation scoring system and got my scores into the Helicone dashboard, where I could compare different requests’ prompts and outputs along with each score.
I also wanted to try out the prompt playground, but at the time of recording the experiment, the playground was broken. A few other buttons didn’t work, like the “Get Started” button that pops up as soon as you create an account.
Besides that, Helicone was a very positive experience. Setup was super easy, and not a lot of code had to be refactored to get Helicone integrated. A few bugs with the UI, but besides that, it got the job done despite not being an evals platform.
Braintrust
Braintrust is an evaluation platform, and I was able to use it as such. The integration into my codebase was very smooth.
For scoring each request’s output, I used heuristic evaluation against the expected output, which Braintrust’s SDK provides.
Within 40 minutes, I was able to get my evaluation workflow set up, and get Braintrust to send my prompt evaluation scores to the dashboard.
I was then able to add traces with one extra line of code.
Overall, the documentation was able to fully guide me through the process of integrating the Braintrust platform into my code. With my input, output, expected output, and evaluation scores all in one place, I was easily able to refactor my prompt.
Arize
Arize was the only platform that I struggled to set up. The documentation had broken links and a layout that made it hard to find what you were looking for.
The plan was to follow the quick start guide for traces. Once they were in the dashboard, I could then create an evals pipeline and start iterating on my prompt.
The reality was a mix of poor documentation, poor instruction, and a lack of coffee…
LangSmith
LangSmith felt very similar to Braintrust, which made the setup quick and easy.
LangSmith doesn’t include built-in heuristic evaluators. Instead, it allows custom code evaluators. It also supports composite, summary, and pairwise evaluations, which are useful for combining scores, averaging results, or comparing outputs.
The documentation was clear, detailed, and included concept explanations and examples (a notable improvement over Arize). Integration was straightforward and user-friendly.
LangSmith is well-designed, easy to integrate, and effective for iterative prompt evaluation. No major complaints as it performs its role reliably and efficiently.
W&B Weave
Weave’s evaluation system mirrors Braintrust and LangSmith: you create an evaluation object with a dataset and score, define a scoring function and model, then run evaluations.
Setup went smoothly, aside from a small logging bug quickly fixed via Cursor.
The platform is geared toward RAG and fine-tuning applications, with strong support for bias and hallucination detection and detailed setup guides. However, this focus means it’s less aligned with your use case and requires more setup steps.
Once running, customizability and usability were excellent. The dashboard nicely formats LLM outputs with collapsible attribute views.
The Matrix of Judgement
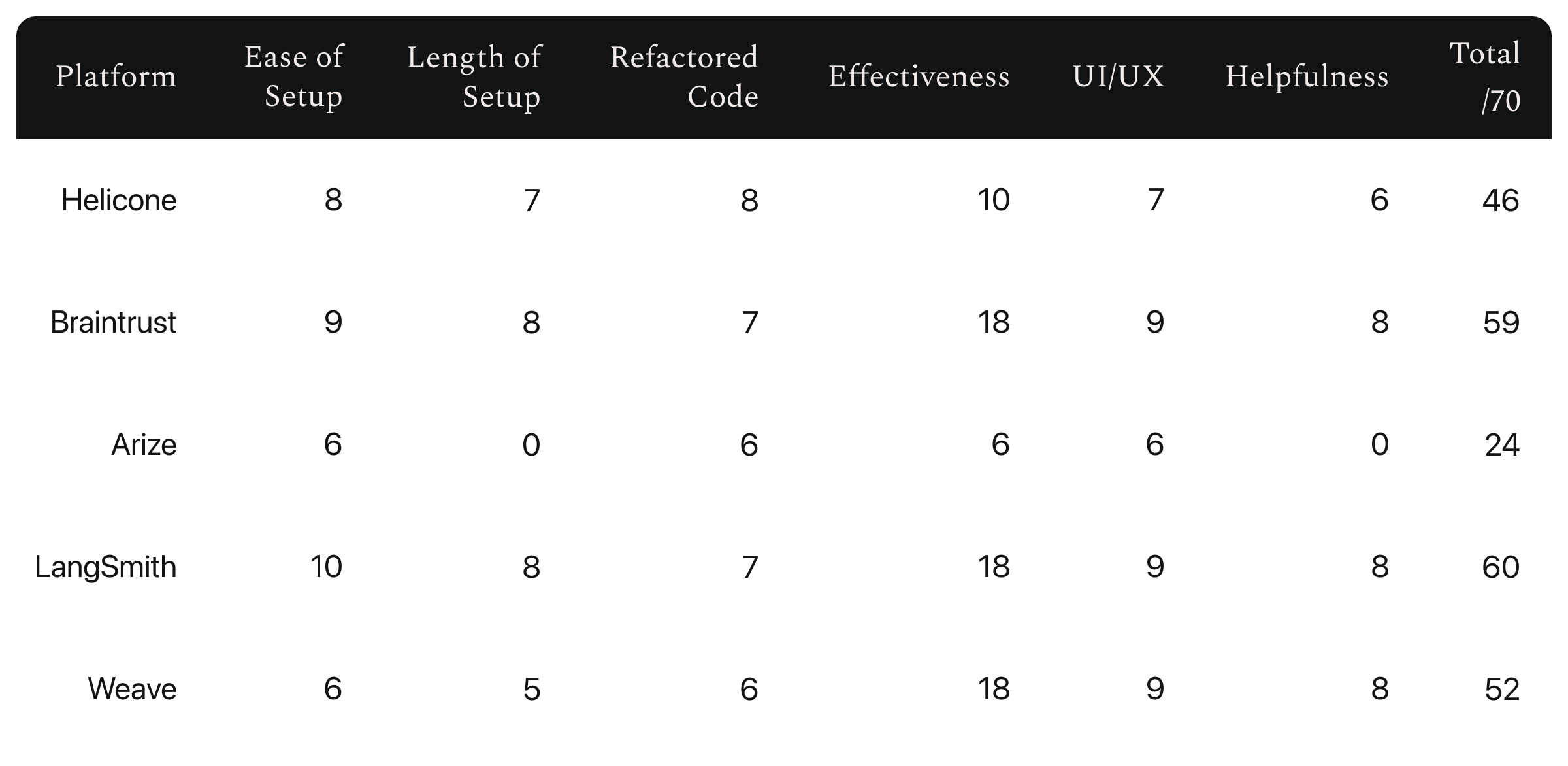
All in all, this was just my short experience with each platform. This wasn’t a full in-depth analysis, so I encourage you to try each of them out yourself. If you are unsure which platform is right for you, here’s an overview:
Helicone excels at LLM observability for dev teams who want quick logging, cost tracking, and debugging with minimal instrumentation. They offer a quick and easy way to switch between LLM providers via their AI gateway. If you want the fastest, lightweight, open-source LLM logging and cost telemetry, go with Helicone.
Braintrust is for teams that want a way to create a structured workflow to evaluate quality, consistency, and monitor live performance of their LLM application. Braintrust bridges prompt/LLM development with quality control and monitoring.
Arize Phoenix is also open-source and allows for deep visibility into complex LLM-based flows. It’s very strong when it comes to diagnosing and iterating your LLM application. If you are in the early stages of developing a complex LLM app and want an open-source option, Arize Phoenix is for you
Like Braintrust, LangSmith is also kind of like an all-in-one package. If you are actively debugging and improving your LLM application, especially if you're already using LangChain, LangSmith is a great option.
If your team is already using Weights & Biases, Weave becomes almost trivial to integrate. If you are doing ML experiments and model tuning with W&B, adding weave allows you full observability and evaluation options for your LLM applications.
Currently, each platform has its own niche that makes it unique. However, I can see a future where each platform’s niche becomes adopted by every other platform. The user experience of each platform is an important differentiating factor, and all platforms should strive to constantly improve it!
Bryan previously reviewed three of these platforms for their evaluation capabilities in a Video Series: 'Mystery Data Science Theatre' with Hamel Husain and Shreya Shankar. View episodes 1, 2, and 3.

