The AI Bezos Mandate

“All teams will henceforth expose their data and functionality to LLMs, and anyone who doesn't do this will be fired.” - Jeff Bezos (theoretically)
Jeff Bezos famously mandated this for web services when starting AWS, and it would be a likely update for the LLM era.
When building for developers, this discipline made AWS services “externalizable by default,” propelled Amazon’s platform strategy, and helped cement microservices as modern dogma.
When building for LLMs, this discipline means having the right context from a variety of systems easily accessible. Although they are incredibly powerful, LLMs are only as intelligent as the context they have.
LLMs Are Limited by Context
At Theory Ventures, we’re investors, but we’re also all builders, creating internal software to move fast. Our goal: answer investor questions about any company in seconds: from “What’s new since the last call?” to “Show revenue by cohort” to “Summarize the last three meetings.”
As a simple example, let’s consider an investor writing a company memo to share internally; information about the company is comprised from several different sources:
- Public and private financial data
- Meeting notes
- Slide decks the company has shared
- PR and social media the company has published
Remembering and managing all of these different data sources and copying them is a lot of work, but what if all that context could be available to the investor’s LLM just by mentioning the company name?
Model Context Protocol (MCP) has emerged as a simple and robust way to give LLMs the right context. MCP is a standardized protocol that empowers LLMs to connect with data sources, tools, and workflows.
A well-designed MCP enables users and agents to complete their work wherever that work is happening: in chat or in a container. MCP is intentionally boring in all the right places: predictable schemas, explicit descriptions, and a clean contract between the system and the model.
Building an AI‑native Platform at Theory Ventures
We deploy an MCP server on FastMCP Cloud so the LLM client can call it from anywhere without custom infrastructure.
LLMs don’t magically know our world. They need:
- The right data sources (CRM, notes, transcripts, structured history, financials),
- clear tools to fetch/transform that data, and
- tight prompts that explain what each tool does and when to use it.
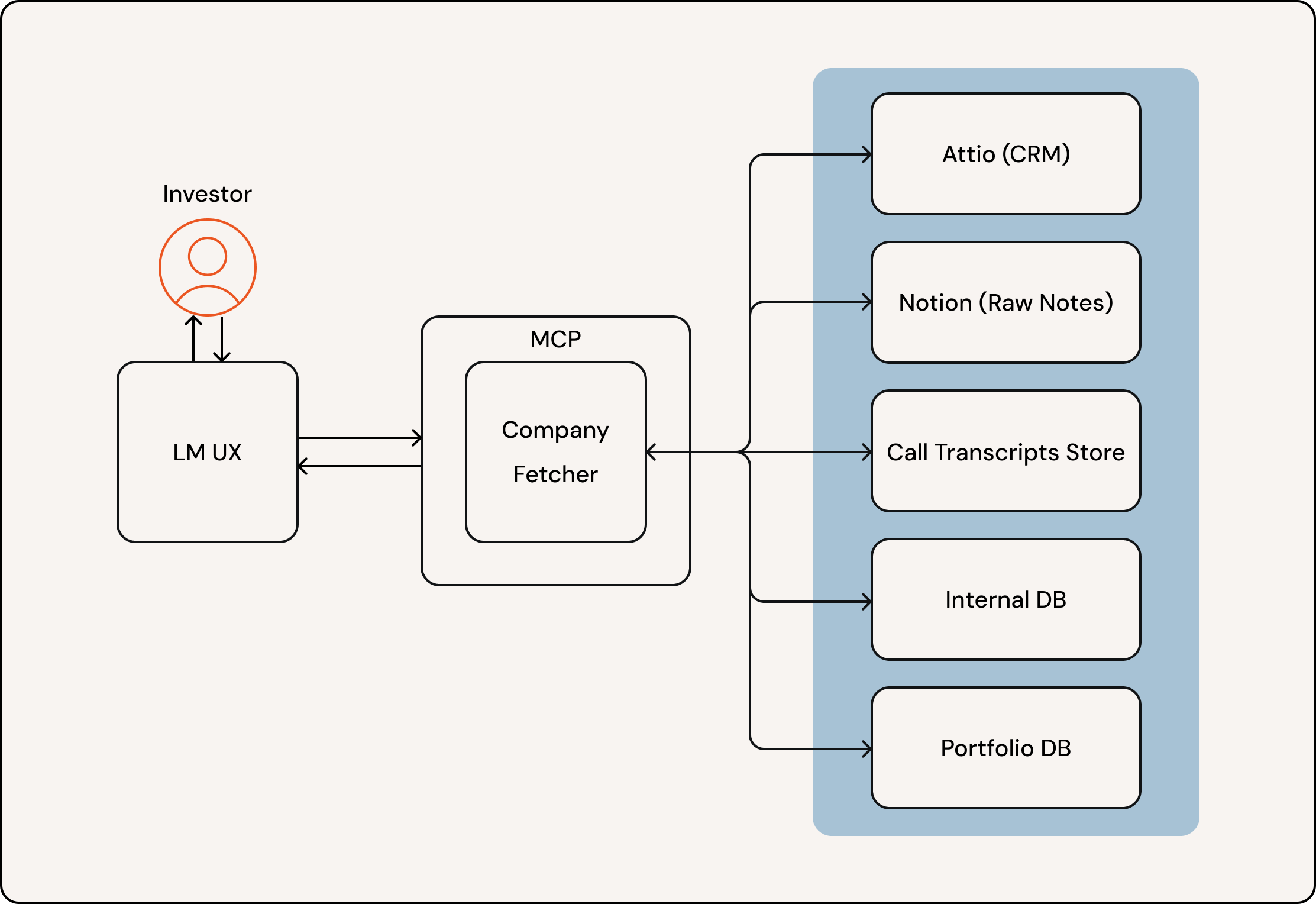
So we exposed one MCP tool that the model can reason about: company_context. Given a company name or domain, it returns a structured summary with IDs, core metadata, notes, historical activity, and (when applicable) financials. Internally, this tool orchestrates multiple services, but the LLM only sees a single, well‑documented interface.
What the tool returns at a high level:
- Core data: name, URL, stage, key contacts
- Unstructured text: analyst/investor notes from Notion
- Meeting transcripts: recorded calls and meetings
- Historical data: structured tables (hires, launches, fundraises, growth KPIs)
- Financials: only for portfolio companies (financial updates and statements)
Here’s the company_context tool’s internal orchestration:
# Pseudocode – orchestrating a company context query
def get_company_context(company_name: str):
company_id = get_company(company_name)
core = fetch_core_company_data(company_id)
notes = fetch_notion_pages(company_id)
history = fetch_historical_data(company_id)
financials = None
if core.get("is_portfolio_company"):
financials = fetch_financials(company_id)
return serialize_company_data(core, notes, transcripts, history, financials)
This tool returns a compact, documented schema so the model knows what it returns and how to consume it. For example:
{
"name": {
"value": "Company A",
"description": "Public-facing name of the company"
},
"id": {
"value": "123444ee-e7f4-4c9f-9a4e-e018eae944d6",
"description": "Canonical company UUID in our system"
},
"domains": {
"value": ["example.com", "example.ai"],
"description": "Known web domains used by the company"
},
"notion_pages": {
"value": [
{"page_id": "abcd1234", "title": "Intro & thesis", "last_edited": "2025-07-28"}
],
"description": "Notion pages with analyst/investor notes"
},
"is_portfolio_company": {
"value": true,
"description": "Whether the company is in our portfolio"
}
}
This isn’t fancy agent pixie dust; it’s just clear contracts that let the model get access to the context it needs without human input.
Architecture Overview
What Comes Next
- Evaluate usage: log how and when the tool is called; refine its name/description/args until calls are near‑deterministic. If you later split the tool, use these logs to design boundaries.
- Improve tool construction: Anthropic recently released a great guide to writing effective tools.
- Guardrails & privacy: add per‑tool auth, redaction, and rate limits. Treat transcripts and financials as sensitive by default.
- Observability: keep traces (prompt → tool calls → outputs → final answer) so humans can audit and improve the loop.
- Better UX: stream answers with inline citations and one‑click pivots (open the Notion page, jump to the transcript, open the CRM record, etc).
If you remember only one thing, make it this: Expose your service’s core functionality as MCP tools and make them excellent. That’s the shortest path to truly AI‑native software. It’s the clearest mandate for the next decade.
