From Model to Machine: Exploring the LLM Infra Stack

1. Introduction and Data Layer
Background
I joined Theory from a product role at an applied machine learning (ML) startup. There, I saw the challenges of bringing ML features to production. Model capabilities were just one small part of the system: performance, reliability, cost, and observability were just as important to the end value.
Over the past two years, large language models (LLMs) have shown incredible capabilities. For many companies, they will be the first large-scale ML models embedded in production applications.
LLMs also create novel challenges. The models are large, slow, and expensive. They require novel systems (e.g. in-context learning) and interaction patterns. Their behavior can be unpredictable.
Bringing these LLM systems to production will require production-ready infrastructure and tooling. Early LLM tooling and design patterns have emerged in prototyping, but this production infrastructure is still being invented.
Foundation model providers have started to build supporting infrastructure around their inference APIs. However, many production LLM apps will have enterprise-level requirements (e.g. around ownership, security, or cost) and complex tech stacks. This creates the opportunity for third-party infrastructure providers – just as we’ve seen in the Modern Data Stack.
This ecosystem is evolving rapidly in technology and market structure. In this series of blog posts, we’ll outline our hypothesis on the key components of that stack, and open questions about how they might develop.
If you are building in this space, we’d love to hear from you at info@theory.ventures!
The LLM infra stack
We believe the LLM infra stack has four key areas:
- Data layer
- Model layer
- Deployment layer
- Interface layer
This is our mental model for understanding the LLM infra stack. It is deliberately a categorical illustration and not a system diagram. Categories will blur and the interfaces across these layers won't be very clearly defined, or even served by separate companies.
LLM infra stack
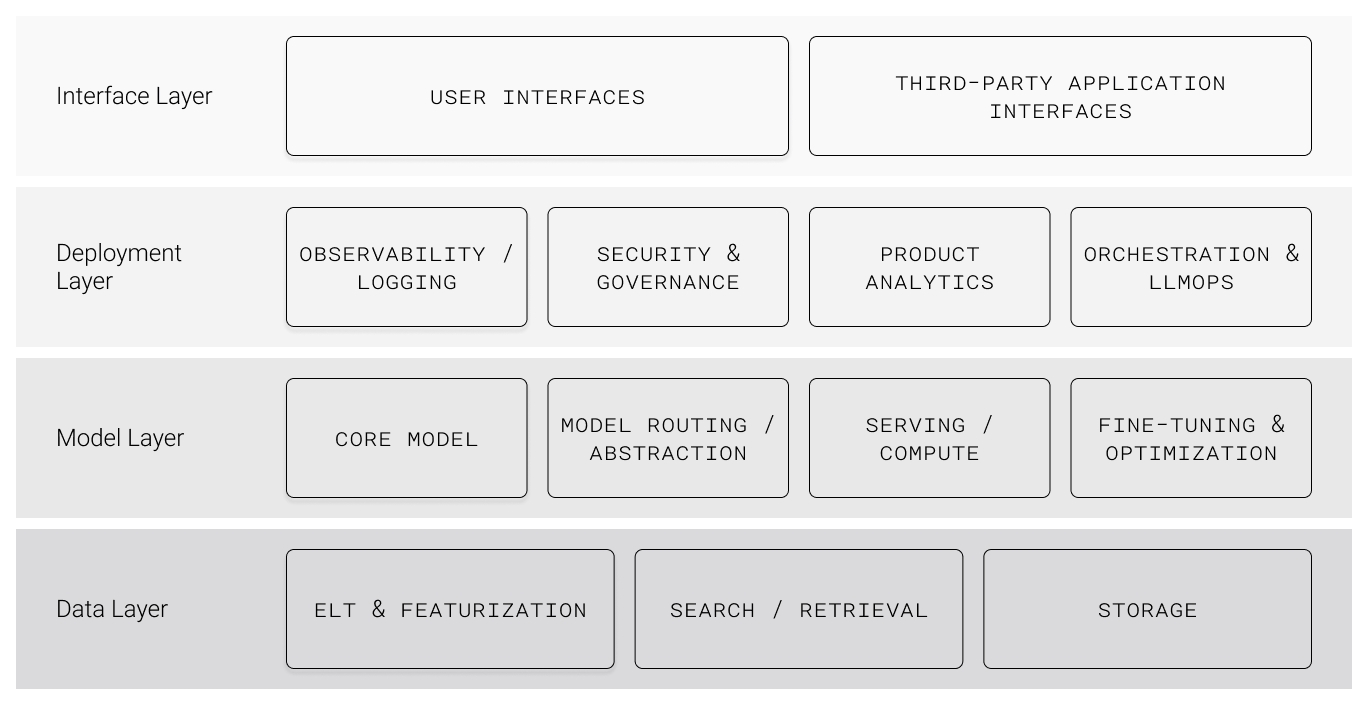
Today, we’ll explore the data layer.
The Data Layer
LLMs are word-prediction machines. For creative writing, the intrinsic word-prediction capabilities of a trained LLM are great. But for most product use cases, they need data. Not just any data, but the right data.
Retrieval-Augmented Generation or RAG are systems that provide LLMs the data they need to respond well. Some examples are:
- Internal documents
- CRM entities
- Customer order history
- Previous queries
RAG allows LLMs to do more while hallucinating less. Instead of predicting the answer based on everything it knows about the world, it can “read” and interpret data provided by the system.
The data layer in this diagram contains the infrastructure to provide the right content to data systems. There are 3 components:
ELT and featurization:
ELT pipelines are designed primarily for analytics/BI consumers. LLM-oriented ELT infrastructure must featurize data for effective search and retrieval.
The prevalent way to featurize data today is to split documents into chunks and transform them into vectors using an off-the-shelf embedding model. This is a simple way to do semantic search.
But we can do much better at storing useful information about our data. We can generate more informative vector embeddings, and partition, index, and pre-process data for subsequent search.
Featurization will need to be intimately tied to how the system plans to store, search, and retrieve data. We’ll discuss that below.
Storage:
Vector embeddings are a critical lookup key for LLM data. They provide semantic meaning of structured and unstructured data in a consistent format that can be efficiently searched.
We have seen an early proliferation of vector databases optimized for this data.
As LLM systems productionize, vectors will remain a critical component of the data stack. It’s possible that we’ll see a new generation of database companies optimized for this workload.
Search / retrieval:
During inference, information must be retrieved and delivered to the model (typically included as part of the prompt). This is the “Retrieval” of Retrieval-Augmented Generation.
The quantity of data far exceeds what can be fit within models’ context windows. If the system does not retrieve an important piece of information, the model cannot access it until the next inference.
Search and retrieval must also be fast enough to support product latency requirements.
To date, approaches have either typically been:
- Simplistic – vector similarity search on naive text embeddings
- Complex – hand-crafted rules-based systems (e.g. Github Copilot, well described in this blog post).
Production LLM systems will benefit from more sophisticated search approaches. There is an opportunity for new infrastructure to enable these without a hand-crafted pipeline.
Key open questions
- How closely coupled will retrieval mechanisms be to initial featurization? Companies may need to be vertically integrated to do so effectively.
- Are storage and search needs unique enough for vector-specific database providers to displace existing ones? At “reasonable scale,” vectors might be stored and searched in file databases.
- How will increasing context window sizes impact the data stack? Cost and latency requirements mean that RAG will always be critical. But increasing context windows may change which featurization, storage, and retrieval techniques are most effective.
- Which companies and use cases will prefer developer-facing data infrastructure to build the Data Layer? Which will prefer business user-facing GUIs?
Companies working on the Data Layer
- ELT and featurization: Superlinked, Unstructured, Waveline
- Storage: Pinecone, Zilliz, Weaviate, Chroma, Featureform, LanceDB, pgvector
- Search/Retrieval: Nomic, Aryn, Metal, Vald, MyScale
- End-to-end platforms: LlamaIndex, Activeloop, Inkeep, Baseplate, Vespa

If you are building in the Data Layer, we’d love to hear from you at info@theory.ventures.
