Why the Business Context Layer Is the Key to Making AI Work in Enterprise

Imagine dropping Einstein into a back-office job at a random Fortune 500 company. Despite his genius, if he didn’t know what the company does or how the role works, he wouldn’t be much help.
AI systems are rapidly improving at work tasks, like summarizing notes, writing queries, and updating slides. But they suffer from the same challenge: knowing how to do work is very different from actually working at a company.
As our models continue to get smarter, how do we get them to be better at doing real jobs?
Building AI automation for enterprises is so complicated because every company operates differently. Even two businesses in the same industry can have distinct processes, systems, and decision-making.
No matter how smart foundation models get, there is no way for them to address this. It’s not an intelligence issue; it requires knowledge of companies’ internal operations, which are proprietary, idiosyncratic, and often undocumented.
So how can we make AI automations work? We need some way to:
-
Understand how an enterprise works,
-
Deliver that knowledge to an AI system, and
-
Maintain and update that knowledge over time.
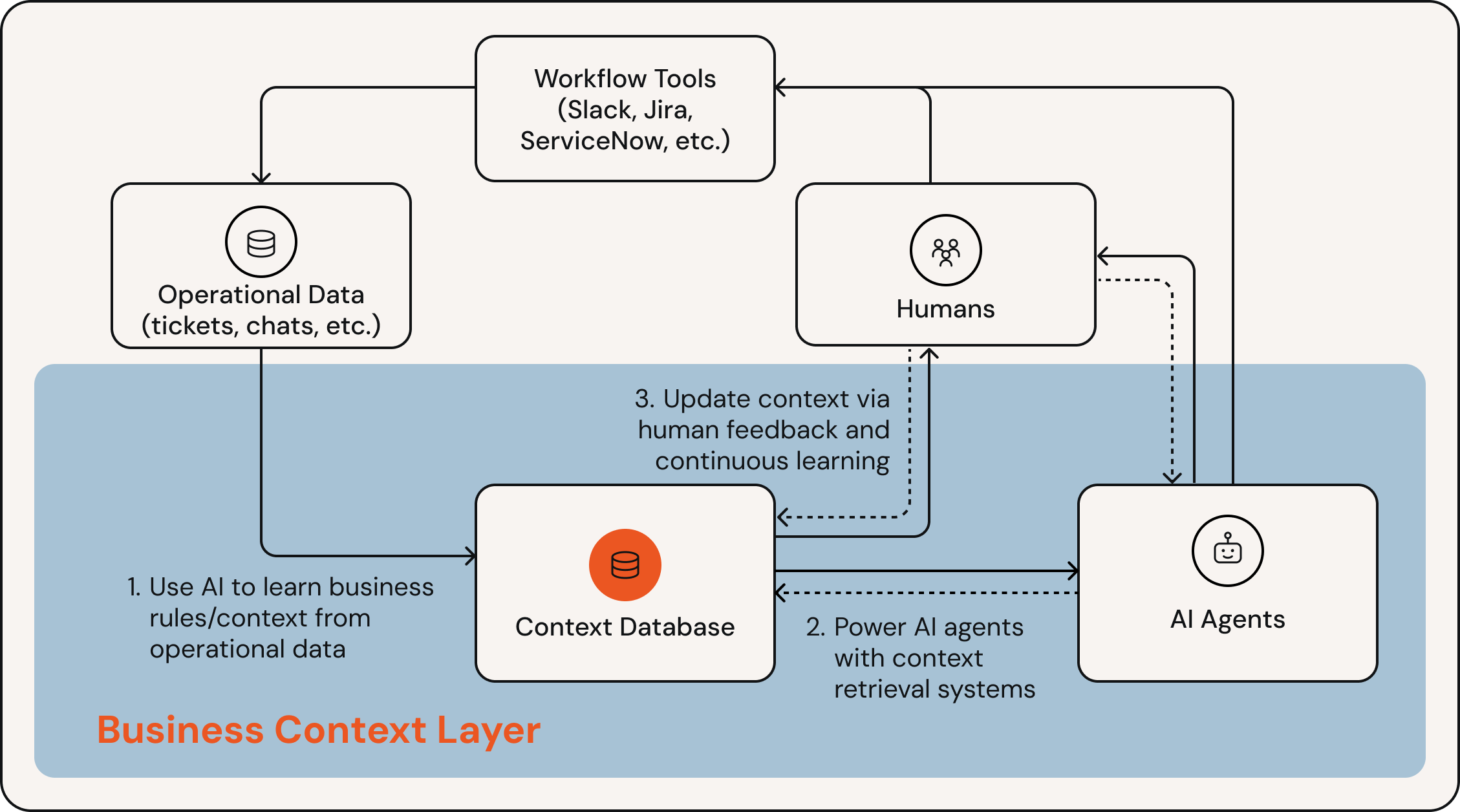
We believe this will create the first major new system of record in years: a Business Context Layer.
What is a Business Context Layer?
Today, a new customer support rep might be told to read a 100-page Standard Operating Procedure (SOP) during onboarding. The SOP includes instructions on how to run processes and handle exceptions: If a customer wants to change account information, always ask for verification. If they ask for a refund, consult these policy rules.
In most companies, these documents are incomplete, outdated, and even contradictory. This leads to teams building tribal knowledge on their own and following processes inconsistently.
When there are millions of AI agents performing complex tasks across the enterprise, we will need something much better: a living system of record that documents all of the written and unwritten rules for how a company operates, and delivers the right instructions to AI systems as they do work. We call this a Business Context Layer or BCL.
We think the key components of this platform are:
-
Automated context extraction/synthesis from operational data: Today’s SOPs are created manually via painstaking process mining, but a future BCL will need to do this largely automatically. This is a complex problem: a system needs to observe human activity (e.g. logs, tickets, chats, or screen recordings), infer a set of rules that describes the behavior, test those rules on real-world data, then iterate on them until they are as accurate as possible.
-
A retrieval system to deliver the right context to AI agents: At enterprise scale, a document describing all of the business rules would be far too large to pass the whole thing to every AI agent: it would be prohibitively slow/expensive, and you would likely suffer decreased accuracy due to context rot. An enterprise-grade BCL will need to (1) index/store this data efficiently, (2) find and deliver the context required to complete a given task, and (3) track what context was used for which queries to inform future improvements.
-
An excellent interface for domain experts to maintain and update context: The BCL must be constantly updated and improved as processes change. Maintaining this knowledge base will become a primary job for humans. This is a complex product to build – it’s got elements of a source control platform like GitHub, experimentation like Statsig, and user-friendly collaboration like Figma. Product & UX will be a major differentiator in the space.
Context vs. RL Environments
In parallel to this emerging context layer, many startups are building “digital twins” of enterprise software and systems. You can let millions of AI agents loose in these simulated environments, provide a goal (e.g., “resolve these support inquiries”), and they will learn how to make business decisions and operate tools via Reinforcement Learning (RL). We think this technique is powerful, but it solves a different problem than a BCL.
Any model fine-tuning comes with trade-offs. You need the expertise and capacity to run training jobs. You need to continuously evaluate and backtest models, because fine-tuning can impact them in unexpected ways. When new models come out, you have to do the whole thing over. RL has all these challenges and more: it is notoriously difficult/unstable to train and very hard to design the appropriate scoring/reward functions, often resulting in unexpected behaviors.
For enterprise workflow automation, there are two other major limitations of the RL approach:
-
It is a black-box: You don’t know what the model learned or why it made a certain decision. A BCL might show a simple learned rule in text: “Anyone having trouble accessing their account should be passed on to the Customer Verification team.” But with an RL system, these learnings will be hidden in model weights.
-
It is not easily modified: Companies are constantly changing their processes, and AI agents will need to, too. Say you want to modify your workflow to “Anyone having trouble accessing their account should first try to reauthenticate with our new portal. If that doesn’t work, then send them to the Customer Verification team.” With a BCL, this change could be made in a few minutes in plain text (then using a testing/eval harness to evaluate the impact). With RL, you might need to update the environment, design a new reward function, re-run training, and then evaluate the impact. That is a long and arduous process.
Our hypothesis is that RL environments will play an important role, but primarily serve large research labs. Using them, foundation models will get dramatically better at doing enterprise work generally: updating CRMs, processing tickets, writing messages, etc. Companies will then use a BCL to provide instructions on how these models should do work at their business – in a human-interpretable, easily-modifiable form.
Building a Business Around the Context Layer
To bring a BCL to market, you need to sell outcomes, not infrastructure. Outcomes are what drive executive urgency. And most enterprises will not be capable of building complex applications with this infrastructure, even if they, in theory, could create ROI.
The clearest value proposition for a BCL is operational process automation and augmentation. Whether an enterprise buys a workflow automation platform or tries to build it internally, the performance out of the box will likely be poor due to a lack of business context. A BCL solves this problem, without requiring teams of consultants and engineers to hardcode information in prompts. It can help automate a much larger proportion of tasks, along with more reliability and controllability.
There are additional value propositions from a BCL: visibility/management (providing leaders with insight into how the organization operates) and productivity (providing front-line workers with additional context or information to do their jobs better), but we think these are secondary to core automation.
Our key questions on the future of the BCL are about the packaging and delivery model:
Standalone system of record vs. vertical applications?
Any AI automation needs organization-specific context to improve performance. Today’s ascendant platforms in customer support, ITSM, sales automation, etc., are already limited by a lack of context. Right now, they solve this primarily through forward-deployed resources, but they will likely try to productize this capability over time.
Will there be a standalone context layer, or will this just be an approach/feature of each enterprise AI app? We think businesses will benefit from a single shared context layer, versus having context siloed across many separate applications, but it remains an open question.
Product-led or services-led?
We think an effective context layer must be created and maintained mostly autonomously. However, building end-to-end automations could still be manual – you might need process discovery to figure out what you should automate in the first place, systems/data engineering to get a solution into production, and change management when a system is deployed.
Companies like Distyl.ai are trying to build a next-generation Palantir: selling complete, services-led solutions built on top of a central platform that can drive recurring revenue and expansion use cases. We think this approach is likely to dominate in the F100, but that there is an equally exciting opportunity to build a more scalable, product-led company for the rest of the enterprise and mid-market.
If you’re thinking about business context for AI systems, we’d love to chat! Send a note to at@theoryvc.com.
