Theories
Stay up-to-date on our team's latest theses and research
Stay up-to-date on our team's latest theses and research
Search is one of the hardest technical problems in computer science. Only a handful of products like Google, Amazon, and Instagram do it well.
Until recently, most products didn’t need great search – it wasn’t core to the user experience.
But with the explosion of LLMs and retrieval systems to support them, every LLM company suddenly needs to have world-class search embedded within their product just to make it work.
With this emerging need, how will this new wave of AI companies solve search?
Retrieval is a critical component of LLM systems, and isn’t going away
Retrieval-augmented generation (RAG) systems deliver relevant information to an LLM to help it respond to a query. This grounds LLM generation in real and relevant information.
Imagine an LLM is answering a question on a history test. Without RAG, the LLM would have to recall the information from things it’s learned in the past. With RAG, it’s like an open-book test: along with the question, the model is provided with the paragraph from the textbook that contains the answer. It’s clear why the latter is much easier.
Finding the right paragraph in the textbook may not be easy. Now imagine trying to find one code snippet in a massive codebase, or the relevant item in a stack of thousands of invoices. Retrieval systems are designed to tackle this challenge.
New LLMs have longer context windows, which allow them to process larger inputs at once. Why take the effort to find a paragraph out of the textbook if you could just load in the entire book?
For most applications, we think that retrieval won’t go away even with >1M token context windows:
Semantic similarity search is just one piece of the puzzle
As LLM prototyping exploded, people quickly turned to semantic similarity search.
This approach has been used for decades. First, separate data into chunks (e.g. each paragraph in a word document). Next, run each chunk through a text embedding model that outputs a vector which encodes semantic meaning of the data. During retrieval, embed the query and retrieve the chunks with the nearest vector representations. These chunks contain the data that (in theory) have the most similar meaning to the query.
Semantic similarity is simple to build, but results in pretty mediocre search. Some key limitations of this approach are:
To the first point, this approach only searches based on the semantic meaning of the query. If you look at any of the companies that do search well, semantic similarity is only one piece of the puzzle.
The goal of search is to return the best results, not the most similar ones.
YouTube combines the meaning of your search query with vectorized predictions of what videos you’re most likely to watch, based on global popularity and your viewing history. Amazon makes sure to prioritize previous purchases in search results, which it knows you were probably looking to re-order.
The future of retrieval systems
Google was founded on the PageRank algorithm, a simple way to rank web pages. But today’s Google search would be unrecognizable to the initial team: it is an incredibly complex system that uses many approaches to return the best results.
Similarly, teams building RAG systems started with simple semantic similarity search. We believe they will quickly become more complex and end up looking like today’s production search or recommender systems. The problems are not that different: from a large set of candidate items, select a small subset that is most likely to achieve some goal.
Today, most retrieval systems look like:

A future system might look something like:
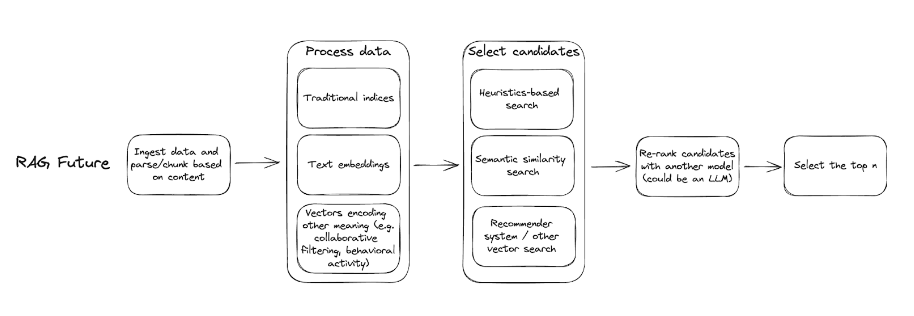
Retrieval systems will have dramatic impacts on the capabilities of LLM applications: their effective memory, response quality, reliability, and performance/latency. We think that for many applications, these systems will have more of an impact on end capabilities than the LLM itself.
Because of this, we think that most companies will build these systems in-house as a core competency and differentiator. These builders will rely on a new set of infrastructure to build retrieval systems specific to their application.
To date, most investment has gone to databases to store vectors and retrieve nearest neighbors. But thinking through a future stack like the one described above, the database is only a small part of the solution.
Building these new systems will require better tooling to:
Although most companies will build retrieval systems themselves, it’s possible that the stack consolidates in a couple ways:
We’re excited for the evolution of retrieval and search as product enablers. If you’re building infrastructure for retrieval systems, or retrieval systems to power a new application, we’d love to chat!
.png)