Theories
Stay up-to-date on our team's latest theses and research
Stay up-to-date on our team's latest theses and research
In a recent post, we described the new era of composable software.
Most knowledge workers spend their day flipping back and forth between isolated pieces of software. Manual work in emails, spreadsheets, and text documents fill the gaps between them.
Large enterprise platforms like Salesforce require hundreds of hours of professional services to configure, and hundreds more to modify. As a result, they are brittle and can’t easily respond to changes to the business.
We believe that we are at the start of a major shift to composable software platforms. These platforms, enabled by modern infrastructure and AI-based automation, will allow companies to configure applications, workflows, and data to their specific business needs.
But what will composable software actually look like in practice? As we’ve dug deeper, it’s clear the composable software movement will not be monolithic. We think there are four key ways companies will make their software more composable in the coming decade.
In nearly every software category, we expect existing systems of record and vertical software will be swapped out for new products built around composability.
Composable, AI-powered products will create magic-feeling automations that would never be possible with an existing platform. From there, customers can design new workflows and integrate additional software without relying on costly services. Value and stickiness will increase as customers build operations around the platform.
Taking on these incumbents requires substantial upfront effort. Companies need to replicate nearly all of existing products’ functionality to be a viable option, while also designing data models, domain-specific languages, and application components that are extensible.
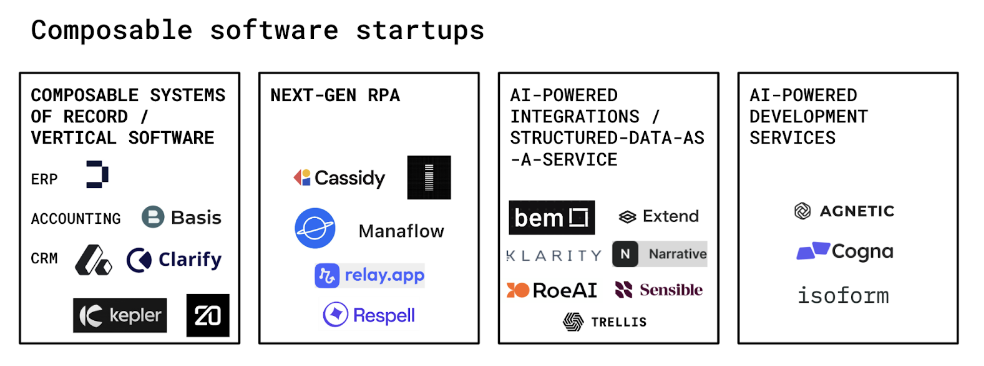
Rippling has dominated in the Human Resource Information System (HRIS) category with a compound product suite. We believe there is an opportunity – and need – to go even further with configurability in more operationally-intense categories like ERP, CRM, and SCM software. Some companies we’ve seen taking this approach are Doss in manufacturing; Basis in accounting; and Attio, Clarify, Twenty, and Kepler in CRM.
Where composable systems of record and vertical software will target the nodes of today’s software graphs, Robotic Process Automation (RPA) tackles the edges between them – the manual workflows of copying and pasting, writing, and double checking information across applications.
RPA is not a new concept, but until recently technology just wasn’t capable of actually replacing human work. LLM-powered automation is different because it can replicate human thinking/classifications and can arbitrarily transform data.
LLM-powered RPA platforms are different enough from legacy RPA that there is an opportunity for new companies to beat out incumbents who bolt on AI features.
Traditional RPA platforms are designed for static tasks like “when a customer submits a complaint form, copy it into a Jira ticket”. Technical moats are mostly driven by integrations.
LLM-powered RPA platforms must be designed for complex multi-step and branching workflows, like “when a customer submits a complaint form, search for similar issues in our database, add the new feedback, then either auto-reply or forward the message to the right department.” Moats will shift to product experience and automation/agentic orchestration.
RPA platforms overlap somewhat with the previous category: for example, a company might consider building out sales automation workflows using either an extensible CRM or an RPA platform. Some differences are:
Some next-gen RPA platforms include Cassidy, Induced, Manaflow, Orby, Relay, Respell, and incumbents like N8n, UiPath, and Zapier.
The most direct reason why today’s software products don’t work together is that it’s too complex to integrate them. The platform might have a sprawling data model that’s hard to parse; it could be a legacy platform without modern APIs. Key information might only be accessible in a generated PDF, or manually typed into a comment field.
Fortunately, one of the most powerful capabilities of LLMs is that they can transform arbitrary data. Whether the input is unstructured (e.g. emails), semi-structured (e.g. PDFs), or structured (e.g. CSVs), LLMs can turn them into reliable structured outputs that can be built into applications.
While LLM outputs are non-deterministic, transformation tasks can typically be done with high accuracy, and are well-suited to fine-tuning. LLMs can also handle variance in input data that would break a deterministic transformation.
As models continue to get smaller, faster, and cheaper, LLM transformations are viable for more real-time and high-volume use cases, like powering transactional marketplaces based on email inputs.
This infrastructure is a key enabler of composable software platforms: as the cost of building and maintaining integrations drops dramatically, it will be possible to couple together more and more software platforms to build workflows around them. They will be especially critical infrastructure in the domains that rely on legacy systems – like finance, healthcare, supply chain/logistics, manufacturing, retail, and real estate.
Some companies building AI-powered transformation infrastructure include Bem, Extend, Klarity, Narrative, Roe, Sensible, and Trellis.
The vast majority of businesses don’t have substantial software engineering capabilities in-house.
These companies will realize many benefits of AI by purchasing AI-enabled software. For example, sales teams will become more efficient with automated prospecting and outreach tools.
They’ll also implement new AI-powered RPA workflows. Customer success teams can use a next-gen RPA tool to ingest customer feedback, classify it by feature or problem type, and route it to the right team for resolution.
But many domain or company-specific use cases require deeper integrations than out-of-the-box software can provide, or more complex workflows than you can build in a UI. Imagine a utilities company that wants to ingest customer outage reports and coordinate repair teams. This could require more complex mapping UIs, routing algorithms, and integration with their ERP and operational software. It probably exceeds what you can buy out-of-the box or configure with an RPA platform or app like Retool.
As The New York Times reported, large consulting firms like McKinsey and BCG have seen appreciable portions of their revenue driven by AI projects. Over time, we expect projects will shift from AI strategy to implementation. This will drive a majority of work to systems integrator firms designed to configure and implement software to address these more complex use cases.
If AI dramatically improves software development efficiency, the market for custom applications will explode. Most companies hire development services firms to configure their ERP or CRM, but wouldn’t ask them to build custom applications – it would be too slow and costly, as these firms are incentivized to sell more hours of work. We expect there will be a set of new AI-enabled development services firms designed to rapidly build and ship new applications on a fee-for-service basis. These will open up a market that is not well-served by the large existing system integrators.
Some new AI-enabled development services firms include Agnetic, Cogna, and Isoform.
Composable software will come in bits and pieces. Walled-garden applications will be replaced with extensible platforms, business users will automate cross-application workflows, and AI will power integrations. It will be easy and cheap to commission fully-custom applications built by AI-enabled services firms.
While their implementation looks different, all these types of composable software work towards the same objectives: better integration of data, and application logic that is tailored for each business versus one-size-fits-all. The result will be massive operational efficiencies – software will automate busy work and let employees focus on what’s most important.
Here’s a (non-exhaustive) map of startups helping drive the composable software revolution:
If you’re building in this space, we’d love to chat at info@theory.ventures!
Since 2020, Theory has conducted a brief go-to-market survey to illuminate the shifts in how startups are pursuing their core markets. We’re launching our 2024 survey now - please find this year’s survey here.
Our goal is to understand how startups have evolved their sales, marketing, customer success, and cash management as we’ve seen a burst of activity from generative AI amidst a challenging macro background. Questions include:
With this data, we will be able to see how the hypothesis of efficiency-orientation among startups has played out through 2024, or if companies are starting to move back into the growth-at-all-cost mindset.
If you complete the survey, we will share with you the anonymized raw data so you can perform your own analyses. If you have questions, message Tomasz on Twitter or info@theory.ventures.
👉 Survey link: https://mvqxr7hlzkq.typeform.com/to/VL6eUZTT
.png)